



强化学习与其他机器学习方法的区别:
- 强化学习无指导数据,只有反馈信息,而监督学习有groundtruth和类标。
- 反馈信息是有延迟的,可用于下一阶段的指导。
- 要处理的数据是时序的
- Agent的行为会影响到其随后将收到的数据。
强化学习的基本模型:
状态:Ot,行为At,反馈Rt
所有的强化学习都是建立在马尔可夫决策过程之上的,即,任何一个强化学习问题都是一个MDP问题。
马尔可夫链:
![]()
其中:

马尔可夫状态转移图:
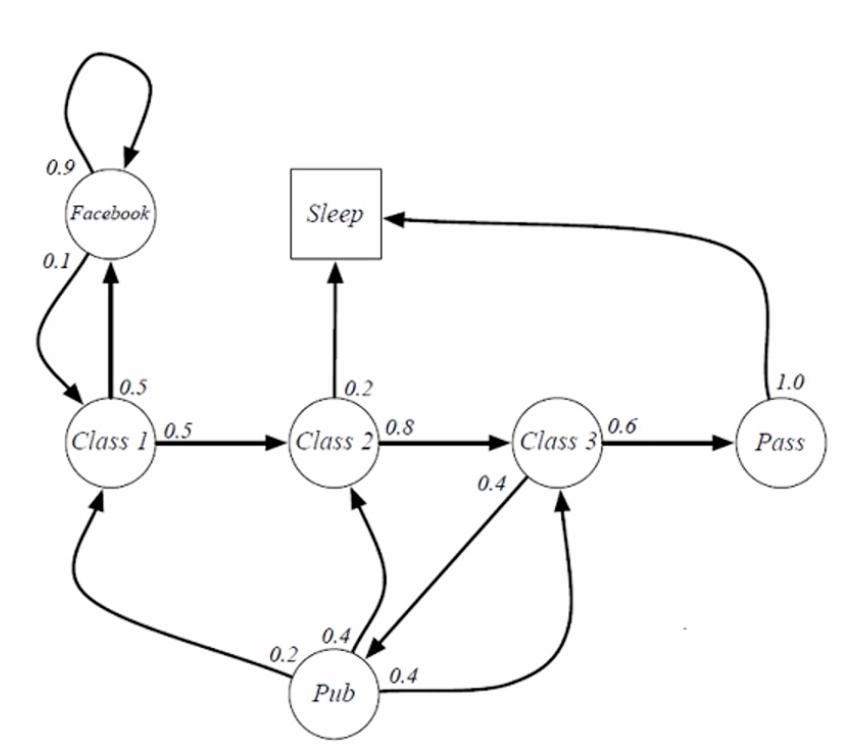
状态转移图对应的状态转移矩阵

马尔可夫奖赏过程(MRP):

马尔可夫决策过程;


 客服1
客服1
 官方群
官方群