affine和linear的区别:
affine是translated linear hyperplane。
perception(bias)->soft perception->other activation function->multi-layer perception(only input layer and output layer)-> deep networks(depth: length og th elongest path from a source to a sink)
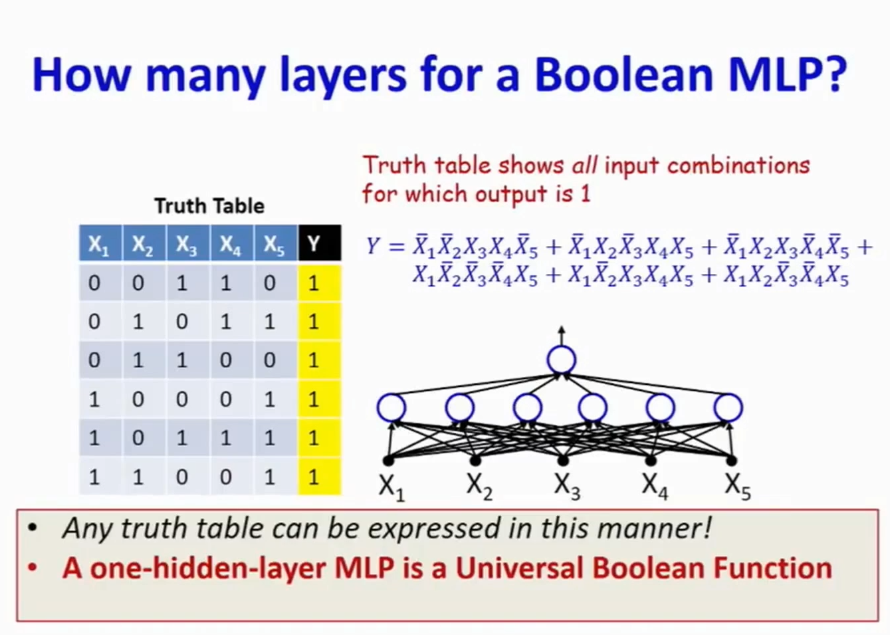
多层感知机(MLP)作为一个执行任意布尔运算的函数-> universal boolean function.
除了通常的与,或,非,MLP还能计算亦或,泛化与,泛化或等计算。
a boolean functio is just a truth table。
一个两层的MLP就可以实现任何布尔函数。实现其真值表即可。
卡诺图可以简化DNF公式,从而得到用来计算该布尔元算的所需最少的perception数量。
一般化的,如果我们只用一个隐层来表达布尔函数的话,那么最坏情况下,最多需要2^(n-1)个perception,n是输入的数量。
如果允许多层的话,那么在最坏情况下,我们只需要2 * (n - 1),实际上是用的xor运算来实现的。一个xor最少用2个perception就可以实现,(如果允许bias为小数的话,如果不允许,就需要三个)那么需要的层数是log_2 n.
这就是为什么需要深度网络的原因!!!减少参数才是关键!
实际情况会更复杂,如果我们要表达的是一个更复杂的函数,













 客服1
客服1
 官方群
官方群