


神经网络:由多个感知机组成的网络。
感知机:仿射函数的和加上 bias T 得到的值和阈值作比较
仿射和线性的区别:
线性函数:过原点,即f(0) = 0
仿射函数:有偏置,因此不过原点,即当仿射的常数项为 0 的时候为线性函数
阈值,也即神经网络的激活函数可以选择的有,sigmoid,softmax,relu等
deep:一个有向图,从源到接收器的**最长的**长度就是“深度”
网络的深度:网络中每一个输入信号在抵达output时必须经历的最长的过程
处理一个问题,需要超过两个以上的神经元则称该网络为“deep network"
神经网络拟合函数:
1. as a Boolean function
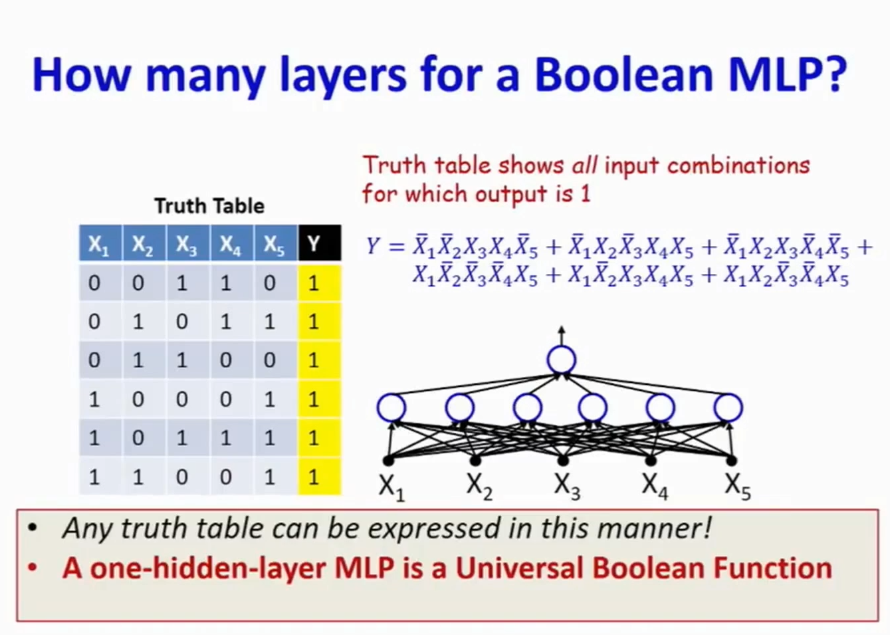
MLP 可以 model any boolean function
只要一层(即没有隐藏层)的神经网络即可表示与门,或门,非门。
而在基础门的前提下,只要再增加一层隐藏函数既可以表示任意 boolean 函数
比如说,增加了一层隐藏层,该层由两个或门感知机组成,一个或门的阈值为1,一个为-1,即可表示 XOR boolean function
但是在数据维度增加的时候,只有一层隐藏层的神经网络的系数将会呈指数级的增长。
这个时候可以通过增加神经网络的深度来使得指数由指数增长变为线性增长。
## Boolean Function 参考知识
DNF公式:[Disjunctive normal form](https://zh.wikipedia.org/wiki/%E6%9E%90%E5%8F%96%E8%8C%83%E5%BC%8F) 析取范式:析取作为最外层,其他的算子只能作为内层,同样的还有合取范式CNF
[卡诺图](https://zh.wikipedia.org/wiki/%E5%8D%A1%E8%AF%BA%E5%9B%BE):真值表的变形,可以将有 n 个变量的逻辑函数的 2^n 个**最小项**组织在给定的长方形表格中。同时为相邻最小项(相邻与(and)项运用邻接律化简提供了直观的图形工具。在部分情况下,卡诺图能让逻辑变得一目了然,但是如果需要处理的逻辑函数的自变量比较多,则卡诺图会变得更加复杂
[真值表](https://zh.wikipedia.org/wiki/%E7%9C%9F%E5%80%BC%E8%A1%A8):列是逻辑的基本操作的取值,而其中某一列或某几列是前面的列取值的结果,即满足 Y = A O B 的表达式,其中 O 表示的是某一种 boolean 表达式










 客服1
客服1
 官方群
官方群