


WtX = |W|x|X|cosb
两个向量的点乘,在计算时采用线性代数的运算法则行向量W乘以列向量X 得出两个向量之间的结果。
找到整个函数的最小值,考虑一阶导数与二阶导数。实际无法一次求得,采用反复迭代的方式求得结果。即函数导数为0点。每次前进方向都为函数导数的反方向取一定的步长。
最后利用交叉熵函数求预测结果y与标定d的相关回传梯度去修正W与b。两个结果之间的相关度使用散度来表示。
¥
支付方式
请使用微信扫一扫 扫描二维码支付
请使用支付宝扫一扫 扫描二维码支付
WtX = |W|x|X|cosb
两个向量的点乘,在计算时采用线性代数的运算法则行向量W乘以列向量X 得出两个向量之间的结果。
找到整个函数的最小值,考虑一阶导数与二阶导数。实际无法一次求得,采用反复迭代的方式求得结果。即函数导数为0点。每次前进方向都为函数导数的反方向取一定的步长。
最后利用交叉熵函数求预测结果y与标定d的相关回传梯度去修正W与b。两个结果之间的相关度使用散度来表示。

对于二分类实际输出层是一个标量就是一个数值。
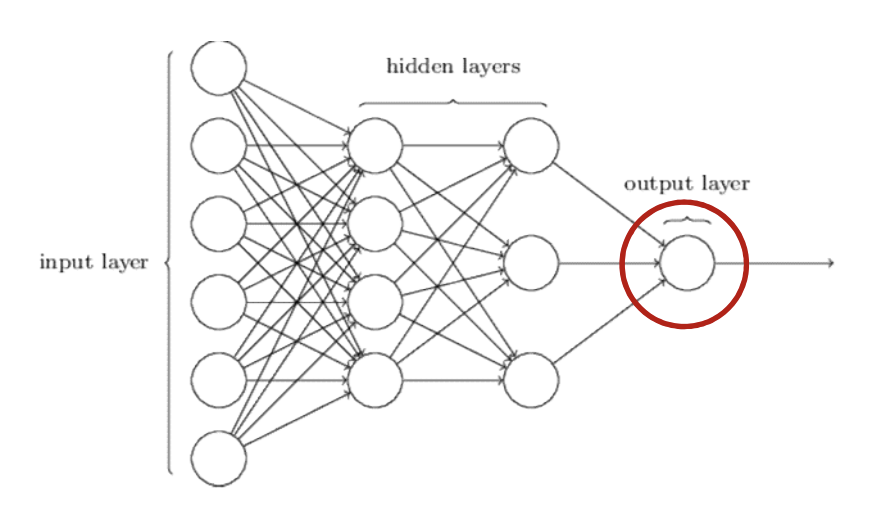
对于多分类实际输出层是长度为类别数量的向量。
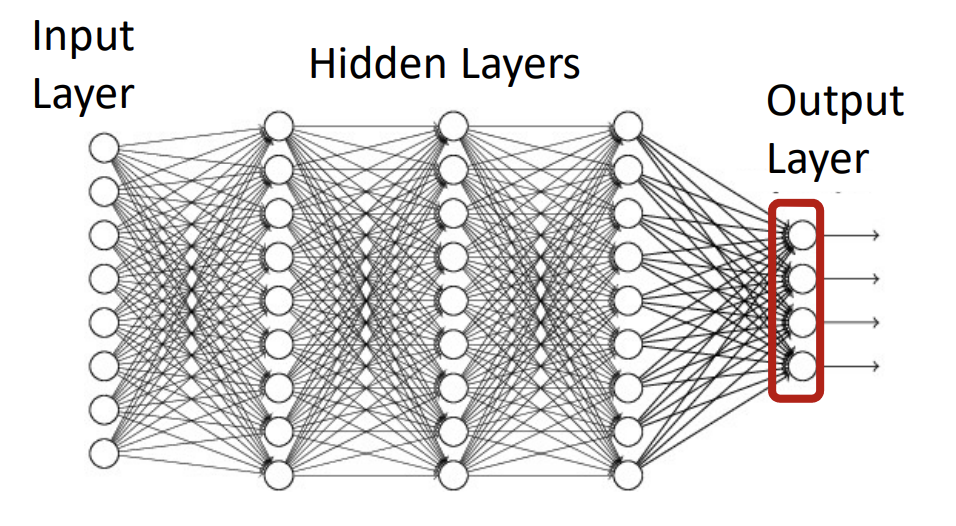
对于分类问题分为二分类与多分类。
在整个过程中是如何通过优化参数使得我们的目标达到最优呢即预测值与真实值的差距最小呢
最主要的实现方式就是梯度下降在每一次的迭代过程后过程中利用上一次的权重&目标函数的导数进行修正最新的权重如此反复使得我们的目标值达到我们的精度要求即可。
这里边涉及到求导、链式法则整体的思想就是当输入有微小变动时这个微小变动能够影响下一层神经元进而这个微小的影响对输出也会有微小的影响。
其实这就要求我们的目标函数、中间的激活函数都是对参数可微的。

vector notation:
Y表示网络最终的输出,即网络的响应。
使用一个阈值函数,比如sigmoid函数,计算y=1的概率。
若是multi-class output:one-hot表示(包含一个1,其他元素都是0):
输出是向量。
softmax层。
————————————————
误差反向传播:
我们会使用链式法则,来计算误差的梯度。
二分类问题:
收敛度量方式:
如果你想要1 0,网络输出是0 1,怎么办?
所以我们经常使用交叉熵来提高效率。
分两种情况:
1、d和y相等;2、d和y不相等。
d是desired output;y是实际输出。
1、当输出的期望d和与样本点实际的标签y相同的时候,散度函数Div(y,d)=0。
2、另d=1,y=0,
-dlogy=-1 * log(0)=-1 * (负无穷)=正无穷
————————————
多分类问题:
需要累加所有的-d * logy,当y和d相同的时候,散度函数Div(y,d)=0;当y和d不同的时候,假设每个分类结果完全不一样的时候,Div(y,d)的结果为无穷大。
只需要计算某一个类的偏导数,其他不用关心。
————————————————————
训练集中所有样本点散度的平均值,就是总误差。
在梯度下降中,每次迭代时,需要用到平均误差来修正其中的变量。在每次迭代中,需要利用上一次迭代的权重以及误差的偏导数来修正更新权重值。
进入小组观看课程
更多 >>



 客服1
客服1
 官方群
官方群