


-
从监督学习到决策任务
-
免模型算法:Q-learning,policy gradients,actor-critic
-
先进的模型学习和预测?
-
exploration?
-
迁移学习和多任务学习,元学习
-
开放问题???
-
深度学习解决复杂环境感知
-
强化学习提供决策(主要针对马尔科夫决策问题-考虑长期效益:如文本翻译,简单决策也可以做:如图像分类,但监督学习已经做的很好了)
-
深度强化学习提供从观察到行动的end-to-end的训练过程
有趣的例子:
-
Atari游戏,输入:图像;输出:向左或右移动
-
捡垃圾的机器手,输入:图像;输出:对机械手的连续控制
-
交通管理,
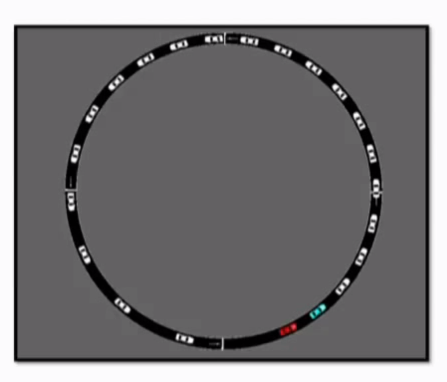
这是一个有趣的例子:只能控制一个车子的前进速度,却要对整个交通进行管理。输入:整个交通车辆状态(这在现实中是不可能已知的,更可能的是已知部分交通状况,而且其变化范围要大的多,但也许依然可以干好呢!);输出:一个车子的前进速度
关键是仅仅一个微小的控制力,就能产生整体的效益
奖励之外的学习
-
基础的强化学习是解决最大化奖励的
-
这并不是序列决策任务的唯一问题
更多的话题:
-
从样例中学习奖励函数(逆强化学习)
-
迁移其他领域的知识(迁移学习,元学习)
-
现实中的奖励来自哪里?
-
从范式中学习
-
直接拷贝已知的行为(模仿学习:自动驾驶,alphago的早期版本)
-
-
-
从观察世界中学习
-
学习预测未来
-
无监督学习(自编码:学习世界的构成原理)
-
-
从其他任务中学习
-
迁移学习
-
元学习:学会学习
-


 客服1
客服1
 官方群
官方群