


所谓一个模型就是一个概率分布,模型中的参数就是概率分布的参数。
比如:
二项分布:参数只有一个p
正态分布:参数有标准差和平均值
线性分布:参数有k和b
高斯分布
泊松分布
...
未知模型:参数有w1,....,wn
所以监督学习是从统计学角度上去进行模仿,而不是智能地学习
st(state) - PI(at|st) 状态动作概率分布 - at(action)
¥
支付方式
请使用微信扫一扫 扫描二维码支付
请使用支付宝扫一扫 扫描二维码支付
所谓一个模型就是一个概率分布,模型中的参数就是概率分布的参数。
比如:
二项分布:参数只有一个p
正态分布:参数有标准差和平均值
线性分布:参数有k和b
高斯分布
泊松分布
...
未知模型:参数有w1,....,wn
所以监督学习是从统计学角度上去进行模仿,而不是智能地学习
st(state) - PI(at|st) 状态动作概率分布 - at(action)
https://zhuanlan.zhihu.com/p/32575824
这个虽然是文科生写得,但是,看完课程再看会有更新的体会
本节主题:
1.定义序列决策问题
2.模型学习(Imitation learning):supervised learning for decision making(决策监督学习)
Q:模仿学习如何工作?
Q:如何让模仿学习工作的更好?
3.模型学习近期的研究案例
4.模型学习缺失什么?
术语:
state和obervation的区别: 以深度强化学习为例(一般以图片为输入),o是指图片中的像素,但在观察的背后有某种对物理现象的总结,所以,状态本质上是你看到这个图像模型时的一个充分概要关于正在发生的事,可用于预测未来而观察是状态相关一个序列。以下图为例:左边的图片分类为老虎,我们把图像o称为观测(observation),输出的结果a称为行动(action);系统要做的是给观测到的图像贴上属性变量的标签,从o到a的过程中有一个策略函数,这个函数给基于条件o,a的概率分布,这个分布比较常见的方式是通过一个softmax函数来确定,这个策略里面有一个参数,如果π是一个神经网络,那么这个参数就是神经网络的权重。在监督学习中我们的目标是找到一组很好的,使其很好的完成任务。
模仿学习
以无人驾驶为例,通过人类获得数据,然后清洗成训练数据,在使用监督学习进行训练,最后输出策略,这个策略可以是行动(转向、油门、刹车)的分布。分布可以是离散的,这时就需要把这些行动离散化;也可以是连续的,如输出转向角度和预期速度的高斯分布。用这种方式能训练无人驾驶吗?不能,训练完毕后,我们显然希望运行的轨迹能够完美切合黑线,但是现实是丰满的,因为实际中总是存在误差,一开始可能会很小,但是误差会积累,因为决策不是单独的问题,每个决策都不是独立同分布的,每个行动都会影响下一个状态,偏移量就很大了,就会出现未知的状态。
总结来说,模仿学习通常有一定局限性(分布不匹配的问题、误差累积问题),但有时候能做得不错,如使用一些稳定控制器,或者从稳定轨迹分布中抽样,抑或是使用DAgger之类的算法增加更多的在线数据,理想化地如使用更好的模型来拟合得更完美。
模仿学习在很多其他领域也有应用。如结构预测问题,不仅仅是输出一个标签,而是更结构化的输出。这种预测问题在自然语言处理,如机器翻译或问答机器人中尤为重要。比如人家提问“Where are you”,回答“I'm at work”。如果像RNN一样一个词一个词输出,如果第二个词at变成了in,那么第三个词可能就不能是work了,即便和数据本身比较接近,可能说school会好一些:第二个词的选择会影响第三个词。因此在结构预测问题中,答案的一部分会影响另一部分,有点类似一个序贯决策问题。因此一些模仿学习方法已经在这个领域中流行了起来:因为通常有训练数据所以会比较像模仿学习,而且是序贯的。其他的诸如交互和主动学习,要从人的反馈中学习;再就是逆强化学习。
那么模仿学习的最大问题是什么?第一,人类需要提供数据,而人能提供的数据通常是非常有限的,即便如头戴摄像机这样相对便宜的手段被开发出来,而深度神经网络通常需要大量的数据才能把事情做好,此为一大限制。第二,人类不善于提供有些类型的行动指导,原因可能是多种多样的。第三,人类可以自主学习而机器则不能,自主学习的好处是我们可以通过自己的经验获得无限量的数据,看到错误可以自我修正,达到连续的自我提升。
1.为什么模型不能很好地模仿专家行为
(1)非马尔可夫行为
(2)多模型的行为
2.如何解决非马尔可夫行为
通过利用历史数据你和RNN和CNN得到拟合参数
3.如何解决多模型的行为
离散action通过类别选择输出多种选择
连续情况则需输出高斯分布,但是在部分模型的情况下,结果不是我们想要的,因此有以下的几种解决方案,从而应对更广泛的问题
4.如何解决多情景的情况
(1) 输出混合高斯分布模型,即在输出时输出多个高斯分布,通过softmax函数实现,不仅仅是一个均值和方差,而是N个均值和方差。每个分布都有一个标量权重,权重之和为1,这种方法叫混合密度网络,对多模型分布的简单设计。但是这种情况只适合低维的模型,即在二维的动作下,才好使用
(2)隐变量模型,比较复杂,但是是多模型分布应用很广泛的方法,这个输出依旧为单高斯分布模型的简单形式,只是在输入的时候添加噪声,噪声是从高斯分布中采样得到,在多模型情况下,将噪声转化为较为复杂的分布,从而改变高斯分布的偏向,即均值和方差,从而做出选择,但是如何将噪声转化为分布,可以查找文献:
a. Conditional variational autoencoder
b.Normalizing flow/realNVP
c.Stein variational gradient descent
在这里困难得原因是网络没有必要使用噪声,因为噪声和输出没有任何关系
(3)自动回归离散,比较简单,但是需要对网络做出多种改变,在训练的时候不需要采样,但是再测试的时候,需要做一次一个维度上的采用(即一次一个维度离散化),并将数值输入到神经网络中,
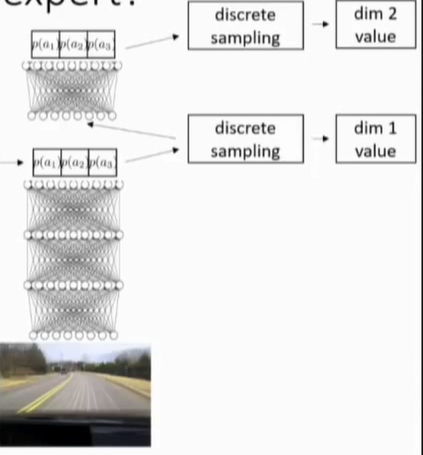
这样可以避免维度灾难,
而以下则为模仿学习的总结
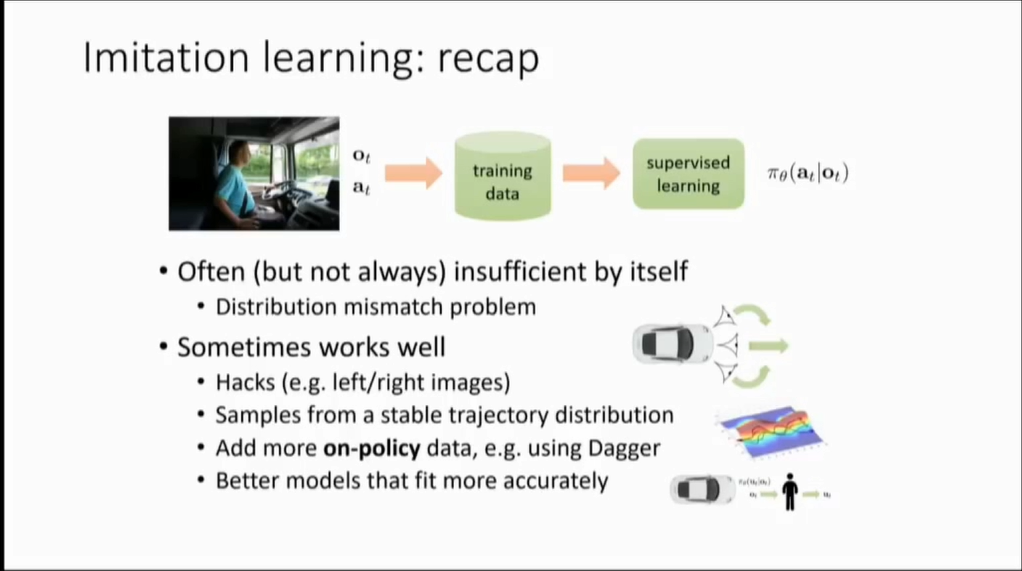
本课从简单的任务说起, 针对一个自动驾驶的问题,分析了可行的策略.
最简单的,模仿学习. 分析了模仿学习理论上的问题和现实中是如何解决这些问题以便让模仿学习可行的.
更为复杂的, 有些问题不能简单的用模仿学习进行训练, 有些问题受困于数据量, 这就引出了本课程的核心, 强化学习.
本课中还给出了强化学习的几个常用记号:
Agent - 本体。学习者、决策者。
Environment - 环境。本体外部的一切。
s - 状态(state)。一个表示环境的数据。
S,S - 所有状态集合。环境中所有的可能状态。
a - 行动(action)。本体可以做的动作。
A,A - 所有行动集合。本体可以做的所有动作。
A(s),A(s) - 状态s的行动集合。本体在状态s下,可以做的所有动作。
r - 奖赏(reward)。本体在一个行动后,获得的奖赏。
R - 所有奖赏集合。本体可以获得的所有奖赏。
St - 第t步的状态(state)。t from 0
At - 第t步的行动(select action)。t from 0
Rt - 第t步的奖赏(reward)。t from 1
Gt - 第t步的长期回报(return)。t from 0。
1 DAgger
1. So far the problems mentioned in the video, besides
1) it is expensive for human to label the data generated by policy
2) it is sometimes impossible for human to be able to give a correct label only by watching a snapshot ( Marcov process is actually a simplified case)
one more problem , in my opinion, is still the exploration and exploitation dilemma. Suppose the algorithm has beed well trained with data , say, from forest, it is hard to work well if the drone fiies to ,say, hill.
2. Non-Markovian Behavior
The reason RL perfers to Markov process may come from the truth that it is easy to calculate and cheap to implement with reasonable memory. You don't have to know much about what had happened previously before you make a dynamic decision.
But human is good at making decision with the help of the accumulated experiences. As a remedy, it is a common way to think multiple snapshots as the current state to input to the network , or to take advantage of RNN to produce the input
DAgger算法总结:
1:根据人类的数据集(观察1,行动1,... 观察N,行动N) 在给定的观察 O下来训练策略π
2: 运行策略π 来得到新数据集(O1,O2,... OM)
3: 根据获取的数据集来给每个数据打上相应的标签a
4:用新的D和新的标签a 来更新新的D,再次训练π,重复整个过程
监督驾驶问题可以通过随机切片解决,这样就防止误差累加,之前伯克利的行走机器人不是这样的吗,效果很不错。
目前的监督学习只是人工智能发展的一个开始,随着任务范围的扩张,无监督学习、模仿学习将会有一个新的发展。更少的人力投入,更多的数据输入,更好的泛化能力。但模仿学习还处于发展阶段,需要更多的理论和实践支持。
大纲:
1、sequential decision problems
从监督学习到序列决策
2、imitation learning
3、关于深度模仿学习的case
Terminology & notation
O:input/observation
S:state(控制论x)
A:output/action 随机分类值,1到n(控制论u)
让我联想到了现代控制理论
在这里,S和O的区别是,S是这个世界背后隐含的状态,O指的是所观察到的图片像素,即表象。
转移函数的定义。
s1 s2 s3:如果你精确地知道s2,那么知道s1或者更早的信息,并不能帮助你预测s3,也无法改进你的决策。此时s3与s1是独立的。因为s2的知识就是你进行预测时,所需要的全部。
结论:如果你能直接观察A,那么知道当前的状态就足够了,知道过往状态对问题并无帮助;如果你在获得O,那么之前的观察结果就可能给你额外的信息。s3仅仅条件依赖于s2,该属性即马尔科夫性质。
——————————————————
imitation learning:
自动驾驶:
不可行:最简单的监督学习方法:behavior cloning,存在偏移问题。如果你有足够多的数据,你可以覆盖Pdata,监督学习的泛化告诉我们,如果我们的数据都是来自P数据,那么我们的误差和P数据是有界的。
怎样能使这个方案可行呢?即,使得
Pdata(o)=Ppi theta(o)
与其把右边那一项改得完美无缺,不如改变左边的那一项,可以改变数据集,消除数据集分布和滑动的分布不一致问题。
这就是DAgger:Dataset Aggregation算法
这个算法很巧妙!!!有点像控制理论的思路。但是这个策略需要在期间,依赖人去给action的好坏打标签。
————————————————————
怎样利用whole history:CNN网络
非马尔科夫行为:不想将所有的数据都传输到前向卷积神经网络中,这样会面临大量的数据通道,大量的weights。
因此,需要设计一个新的神经网络。共享所有卷积编码器的权值。LSTM cells work better。
多模型行为:使用高斯分布实现。平均平方误差是高斯分布的对数概率。若使用平均平方误差,即使用了高斯分布。
如何解决:
1、output mixture of Gaussians
N个均值,N个方差。且对所有的分布都需要有一个标量权重。所有标量的总合为1(softmax)。混合密度网络,对多模型分布的简单设计。
适用:不能用有限数量的分布元素来表示任意的分布。在低维度的情况下,假设你有一个或者两个维度的行为决策,这个方法将会非常奏效。若你有非常高维度的行为决策,那么这个方法就会非常脆弱。
2、latent variable models使用隐变量模型
复杂,但用于学习多模型分布时,应用广泛。
输出不变,仍然以一种像单高斯分布模型的简单形式存在;但是给神经网络在底部接入额外的输入(随机数)。给神经网络一些随机源,这样就可以利用这些随机性来训练网络,以实质地改变输出的分布。
神经网络是一个普适的函数逼近器,它可以把噪声转换为在输出时的任何分布。
利用噪声,呈现复杂的分布。
3、自动回归离散化。实现简单。
离散:softmax
连续动作决策:若你离散化的是高维度的连续变量,就得面对维数灾难了。两个维度的决策,很好离散化;但若变成十个维度呢?你将面对很多不同维度的离散化数值,很有可能会用尽内存。
自动回归离散化通过一次只离散化一个维度来实现。1)先处理第一个维度,对其离散化并使用softmax,从分布中采样,得到行为决策的第一个维度结果。2)给其他神经网络这个结果。结合我们从第一个维度的所有采样以及第二个维度的条件,来预测一个离散化结果。然后重复。直到对所有维度都完成了采样。
这里的维度是线性增长,并不是维数灾难,维数灾难指的是指数型增长。
——————————————————
模仿学习:
飞行;机器人控制。
structured prediction:机器翻译;
逆强化学习
——————————————————
模仿学习的问题:
1)人们需要给模拟学习提供数据,但是数据是有限的:deep learning在数据充足的时候效果最好。效果与数据正相关。
2)人们在有些任务上,不擅长提供决策。
3)人们可以自动学习。机器是否也可以?通过自身经验获得无限的数据;持续学习以获取持续改善。
——————————————————
在模仿学习中,目标很简单,只需要复制人们示范的。但若是自主学习,目标则不同。自主学习需要构建cost function or reward function。
———————————————————


 客服1
客服1
 官方群
官方群