


content:
1. Sequential decision problem;
2. Imitation learning: supervised learning for decision making;
3. Strengths and weaknesses of Imitation learning;
symbol:
pi: distribution
theta: the parameters of a distribution
pi(a|o) partially observed, just observation
pi(a|s) fully observed, underlying state of the world
sequential decision:
conditional independence, given s2, we have a2, you can not get more precise information even if you know s1.
DAgger:
goal: collect traing data from pi_theta(a|o);
run pi_theta(a|o) to get o;
label dataset o;
aggregation and repeat;
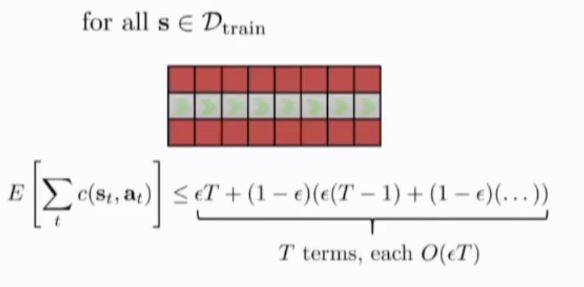
DAgger addresses the problems of distributional drift.
Problem:
1. non-markovian behavior
2. multimodal behavior
Solution:
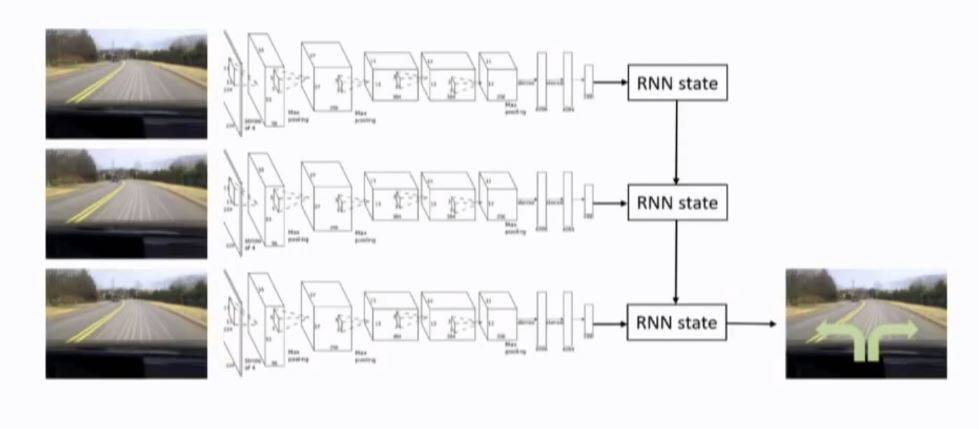
1. RNN neural network to use history information. behavior depends on past observations.
2. Output mixture of Gaussians
3. Latent variable models
4. Autoregressive discretization
Imitation Learning:
imitation learning can sove sequential decision problem, however, due to distribution mismatch problem, sometime it is insufficient.
Some topics in imitation learning:
structured prediction
inverse reinforcement learning
Maths behind it, need books, paper and pen!


 客服1
客服1
 官方群
官方群