


http://christophm.github.io/interpretable-ml-book/师兄推荐的一本书:Interpretable Machine Learning
¥
支付方式
微信支付
支付宝支付
¥
请使用微信扫一扫 扫描二维码支付
¥
请使用支付宝扫一扫 扫描二维码支付
注:本文笔记根据2020年课程所写,但很多还不明白,新版框架更清晰,但没有讲local bias,可能是放在前面几节课讲,先放到这里以后再开
STRUCTURE PREDICTION
- 一种问题
- 等长序列标注任务
- 不等长序列生成任务
- sequence maxinum likehood 两种normal的不同差异
- local normalization
- 单个单词可能性的乘积
- 优点速度快
- 但容易陷入错误的解,特别是进入到选项比较少的情况新版本删掉
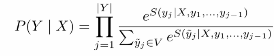
- global normalization 能量模型
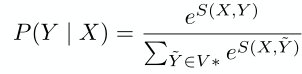
- 整个句子的概率
- 最优解但softmax速度慢
- 结构化模型用动态规划 crf cfg
- partition function配分函数sampling
- sampling:采样k个samples做配分函数
- 无偏估计
- 高方差
- 预测用的:beam search k个最好的假设
- 我的想法:这步好像避免求概率,score就可以
- 有偏估计
- 低方差
- sampling:采样k个samples做配分函数
- local normalization
- unnormal 模型
- 什么时候需要normal
- 下游需要知道你这个预测的准确率,可能性的时候
- 额外知识:概率模型校准
- 输出的概率和输出的可信度成直线正比 538
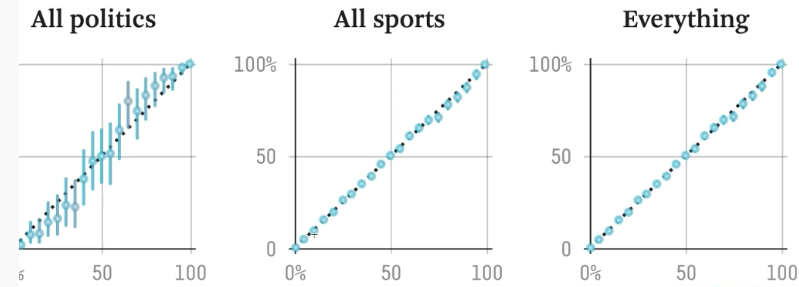
- 神经网络输出很高,但置信度不是很大
- 输出的概率和输出的可信度成直线正比 538
- 下游需要知道你这个预测的准确率,可能性的时候
- 推断的时候我们不需要知道概率
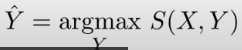
- 什么时候需要normal
- 非结构化方法:重复的multi classify
- independent classification

- 有一篇论文采用这种独立的分类对序列化模型crf做模型蒸馏,速度更快
- 不考虑输出信息的bilstm不算结构预测
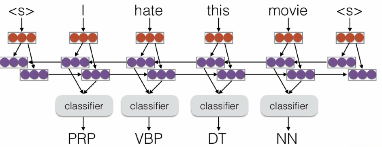
- 但我觉得内部信息有整体结构信息流动
- independent classification
- 结构化预测:利用信息和输出的结构信息
- 会帮助选出整体可能性最好的结果,高效
- 结构化感知机 structured perceptron
- loss
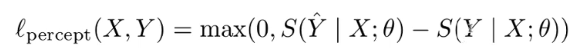
- 对比

- 我自己的理解softmax是一种梯度的分配,更新所有样本,相当于全局的global loss
- structured training pre-training
- 可以先用概率模型 更新所有样本,再用structure更新一个样本,避免exposure bias
- margin hinge loss
- svm
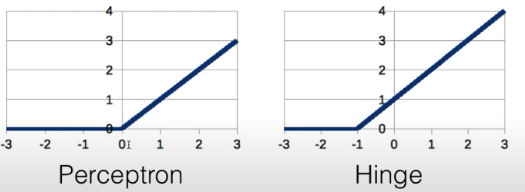

- 这里提了一点:hinge损失会找到中间平衡值
- 而交叉熵不会对负样本做出惩罚,会更偏向正样本
- Cross-Entropy Loss Leads To Poor Margins
https://openreview.net/forum?id=ByfbnsA9Km
- Cross-Entropy Loss Leads To Poor Margins
- svm
- cost augmented hinge
- 错误的代价是不同的
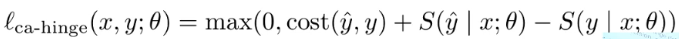
- costs over sequences
- zero-one loss
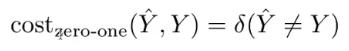
- hamming loss
- 一个元素一个错误
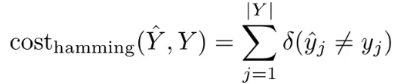
- 一个元素一个错误
- other losses
- edit distance 1-bleu
- zero-one loss
- 错误的代价是不同的
- structured hinge loss
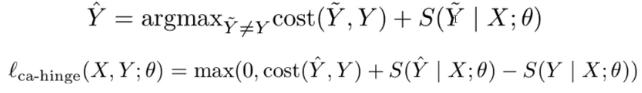
- 这里可能还是对训练说的,推测时我们不知道目标Y
- hamming loss
- 训练中损失+1,增加了一个margin,针对 exposure bias
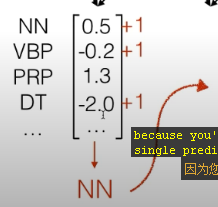
- 训练中损失+1,增加了一个margin,针对 exposure bias
- 对比
- 更新
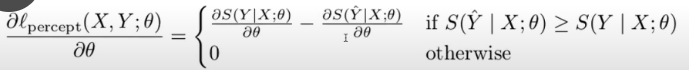
- loss
- exposure bias
- 问题:teacher forceing
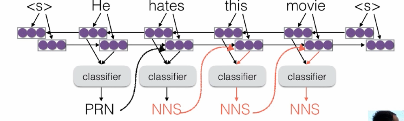
- 我们一直再给序列输入前一个正确的输出,这样实际中模型会严重依赖前一个输出,如果实际中预测错误,会严重影响后面的预测
- 类似bert训练中的mask不在实际预测中出现
- 解决办法
- 感知机算法
- 忍受exposure bias 的pretrain 更有效率
- more complicated algorithm : cost hinge loss 的结构化感知机fine tune
- sample mistakes in training
- dagger 不使用预测的输出
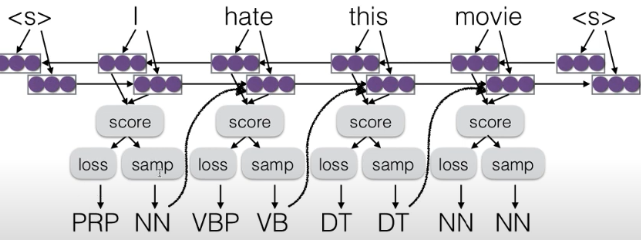
- scheduled sampling pretrain
- 一开始不采样错误,后来引入错误
- 用于语音识别非常好,因为你不确定你听到的到底是什么
- scheduled sampling pretrain
- dynamic oracle
- 用于机器翻译
- dagger 不使用预测的输出
- drop out inputs
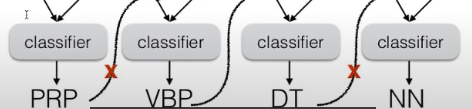
- 不太依靠上文输出
- 更多的选择 :corrupt training data
- reward augmented maximum likelihood
- 制造错误样本输入 好处不学习0 学习错误的 更现实
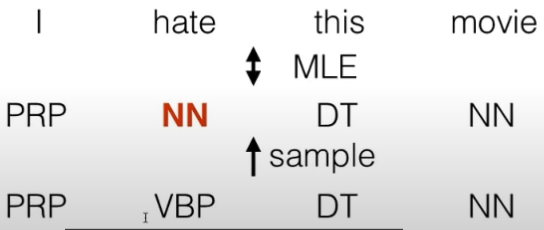
- sample 概率与cost成反比,更愿意sample cost为0的词
- 感知机算法
- 问题:teacher forceing
language is hard:语言有很多规则,要分语境,时态,要考虑上下文
解决方案:定义语法规则(不考虑机器学习),时态规则,语义分类,以及偏好
BOW:词袋模型
CBOW:连续词袋模型
了解nlp,自然语言处理中自然的意义
希望ai研习社能找到机器学习的nlp课程
以对nlp内容打好基础
文本分类的简单问题
对每个类别进行打分 取最高分作为分类
构建函数提取组合特征
cbow连续词袋 特征组合应用
基本上这个模型是:取特征加和特征 成权重矩阵+bias 转化成得分
Deep CBOW
模型(提取组合特征 一个消极和积极的单词是否出现在一个句子里)
一句话中特征加和变成特征向量但不是使用特征向里来预测 而是通过一个几层的非线性函数运行这个模型然后基于多重特征层乘权重矩阵在加上偏差求出得分
ps:快通过啊 需要解锁卡看下一节
随堂笔记:
1. 语法规则和语义理解的问难
2. 特征词的存在: 例:情感分类--love, hate;否定词;
3. 词袋模型 -> 连续词袋模型 -> 深度连续词袋
线性组合 -> 非线性表现(可提取组合特征)
4. 神经网络相关
:- 抽象于生物意义上的神经元。输入神经元,接收信号,达到激活程度,产生输出。
:- 计算图表示。
:- 神经网络框架:theano, caffe, mxnet, tensorflow(静态); dynet(适合复杂任务), chainer, pytorch(动态)
:- 过程:创建模型->对每例,创建计算图,训练,反向传播,更新参数
静态和动态的代价取舍
静态:计算快速,移植方便
动态:操作灵活,流程简单
:- 示例(情感分类, stanford情绪):
1)读入训练集,得到单词和标签
2)定义模型(net框架),定义参数(参数=单词数量*标签数量)(权重矩阵,偏置矩阵)
3)训练,反向传播,更新参数
(和之前的基本操作过程相似,只是顺手记录)
:- 调参可以尝试不同的方式计算分数,例如修改单词的embeddings大小;设置不同的权重矩阵;修改隐藏层参数
如何完成句子的分类?这个就是句子分类的任务,将句子分为5个类别,我们可以使用词袋模型来完成这个任务
将每一个单词使用词袋模型表示向量,每个向量的维度都是5(我是这样理解的这个语料库中词的数量只有5个,所以词典大小就是5),然后加起来就是整个句子的向量,然后我们就可以使用这个向量完成softmax的分类了,但是这样的词袋模型完成分类会有一些问题,因为我们是一个词一个词的在向量表示,很有可能出现don‘t like的情况
出现这种情况的原因是don’t‘单独向量化了,然后love单独向量化了,二者并没有结合在一起
而神经网络可以解决这个问题,它可以将元素特征进行组合
我们不对每一个bow向量进行相加,而是把它们放到神经网络中得到score得分,然后进行softmax分类,得到最终该文本的类别
这个是连续词袋模型,将每个词的向量加起来之后,乘以一个矩阵W,假如加起来的词的向量维度是100维,那么w的维度就是5*100,所以最终的输出维度为5维的向量,正好完成分类任务
这样处理只是降低了维度,仍然是线性表示,仍然没有组合特征,如何才能组合特征?
Sentence Classification
- Bag of Words (BOW)
- 每个单词都有这五种element 相关度 [very good, good, neutral, bad, very bad]。
- 最简单的做法就是将句子中每个单词对于这些 element 相关度加总,可以取最高值来当作这个句子的表现。
- 当句子有特定字词可能会来改变结果 (例如:don't, nothing...)
- 可以透过 neural net 来 extract combination features
- Continuous Bag of Words (CBOW)
- 将每个单词相转换成许多 features (例如:positive words)
- 将 features 加总后,透过这个 features 来预测这个句子的 element
- Deep COBW
- 透过运算来将不同的 feature 进行 combine,再来透过这个结果来预测这个句子的 element
Nerual Network Frameworks
- Static Frameworks
- theano
- Caffe
- MXNet
- TensorFlow
- Dynamic Frameworks
- Dynet
- Chainer
- PyTorch
- 优点:有灵活操作空间
- 缺点: 计算量大
Basic Process in Dynamic Neural Network Frameworks
- Create a model
- For each example
- create a graph
- calculate the result
- back propagation an update
实验内容学习
1、环境配置
第二讲之前要先进行一下实验的学习。因为第一讲内容的编码使用的是pytorch 所以要先进行安装。但是anaconda国内镜像(清华和科大)已经停止更新和维护,因此需要恢复原chanel方法是:conda config --remove-key channels
重新配置默认源
但是安装速度很慢,有两种方式解决
(1)pytorch1.1的源文件很大有427M,我参考了网上的方法并改了下参数下载速度很快,使用pip命令进行安装。
pip install http://download.pytorch.org/whl/cu90/torch-1.1.0-cp36-cp36m-win_amd64.whl
实践证明是可以这么安装的,但是anconda更新的时候,却仍然要在更新一次,但我感觉应该也可以用。
(2)如果发现试了两次安装仍很慢,赶紧使用其他运营商的线路进行更新。在我十多次使用移动家庭宽带无法更新后,我使用校园网的VPN更新时仅尝试一次就成功更新。因为校园网是双路由选择,所以及时换线路,在https://pytorch.org/ 官方网站上找到命令,使用conda install 命令进行更新就可以。
2、代码测试
课程代码地址为:
https://github.com/neubig/nn4nlp-code
先做完第一节的内容,再做第二节
本节内容
本节内容主要是讲解LSTM在编码过程中的debug、run过程中的调参tricks和一些其他的策略,包括minibatch的选择、dropout、学习策略的选择等。
大部分内容都可以在论文regularizing and optimizing LSTM language Models中找到
# (CMU CS 11-747 Week 2) Language Modeling 语言模型
标签(空格分隔): NLP CMU MOOC DeepLearning CS-11747
---
个人理解,语言模型的问题本质就是如何判定一句话是否通顺
个人理解,语言模型的问题本质就是如何判定一句话是否通顺
## 1. Count-based Language Models 基于计数的语言模型
略去
略去
### Problems and Solutions
* Cannot share strength among **similiar words**
Solution: class-based language models
* Cannot condition on context with **intervening words**(上下文相同)
Dr. Jane Smith Dr. Gertrude Smith
* Cannot share strength among **similiar words**
Solution: class-based language models
* Cannot condition on context with **intervening words**(上下文相同)
Dr. Jane Smith Dr. Gertrude Smith
Solution: skip-gram language models
* Cannot handle **long distance dependencies**
Solution: cache, trigger, topic, syntactic models
## 2. Featurized Log-linear Models
* Calculate features of the context 提取文本特征
* Based on the features, calculate probabilities 计算概率
* Optimize feature weights using gradient descent, etc. 利用梯度下降优化特征权重
* Cannot handle **long distance dependencies**
Solution: cache, trigger, topic, syntactic models
## 2. Featurized Log-linear Models
* Calculate features of the context 提取文本特征
* Based on the features, calculate probabilities 计算概率
* Optimize feature weights using gradient descent, etc. 利用梯度下降优化特征权重
![ApplicationFrameHost_3KLbZh5fM5.png-103.7kB][1]
之后再将得到的score利用`softmax`计算为概率
之后再将得到的score利用`softmax`计算为概率
计算图可表示如下:
![ApplicationFrameHost_7TdihjnEGj.png-80.1kB][2]
![ApplicationFrameHost_7TdihjnEGj.png-80.1kB][2]
### Lookup 查找
![lookup.png-292.8kB][3]
两种方法:
* 第一种使用index, 时间复杂度为O(1), 更有效率更好
* 用 (vector * num\_of\_words) 与 one-hot vector 相乘,得到最终的word vector
* 用 (vector * num\_of\_words) 与 one-hot vector 相乘,得到最终的word vector
### Training a model 训练模型
loss function 我们一般选取 `negative log likelihood`,这样选取的原因是算法更喜欢计算最小值(直接用导数值为0即可),因此对`p vector`中的最大值直接取`-log`即可,如下图所示:
![ApplicationFrameHost_mjrJo4kTqV.png-35.8kB][4]
loss function 我们一般选取 `negative log likelihood`,这样选取的原因是算法更喜欢计算最小值(直接用导数值为0即可),因此对`p vector`中的最大值直接取`-log`即可,如下图所示:
![ApplicationFrameHost_mjrJo4kTqV.png-35.8kB][4]
### Parameter Update 参数更新
使用的是反向传播算法,计算的是$\frac{\partial l}{\partial \theta}$, **这里还不太懂**,使用SGD来优化的话,参数更新的方程式就是这样的:
$$\theta \leftarrow \theta - \alpha\frac{\partial l}{\partial \theta}$$
### Choosing a Vocabulary 选择词库
如果希望比较不同的模型,请确保它们的词库相同。当然,基于char和基于vocabulary的模型是可以放在一起比较的,因为基于char的模型它可以生成基于vocabulary的模型。
#### Unknown Words
一般应该设定在`word_freq`小于某值时(例如5),就将它设为`UNK`,因为这样可以显著减少词库个数,以及最后的权重矩阵大小。当然也k可以使用rank threshold, 使用自己定义的rank来排除掉最后rank低的单词,将他们定义为`UNK`。
使用的是反向传播算法,计算的是$\frac{\partial l}{\partial \theta}$, **这里还不太懂**,使用SGD来优化的话,参数更新的方程式就是这样的:
$$\theta \leftarrow \theta - \alpha\frac{\partial l}{\partial \theta}$$
### Choosing a Vocabulary 选择词库
如果希望比较不同的模型,请确保它们的词库相同。当然,基于char和基于vocabulary的模型是可以放在一起比较的,因为基于char的模型它可以生成基于vocabulary的模型。
#### Unknown Words
一般应该设定在`word_freq`小于某值时(例如5),就将它设为`UNK`,因为这样可以显著减少词库个数,以及最后的权重矩阵大小。当然也k可以使用rank threshold, 使用自己定义的rank来排除掉最后rank低的单词,将他们定义为`UNK`。
## What Problems are Handled?
* similar words -> Not solved!
* intervening words -> solved!
* handle long-distance dependencies -> Not solved!
* similar words -> Not solved!
* intervening words -> solved!
* handle long-distance dependencies -> Not solved!
---
**Linear Models Can't learn Feature Combinations**
farmers eat steak -> high farmers eat hay -> low
cows eat steak -> low cows eat hay -> high
cows eat steak -> low cows eat hay -> high
What could we do?
* Remember combinations as features (N-gram) -> 导致内存爆炸
* Neural Nets
* Neural Nets
## 3.Neural Language Models
---
![ApplicationFrameHost_t6cjfefnAF.png-250.8kB][5]
### 1. What Problems are Handled by Neural Language Models?
* similar words -> solved
* intervening words -> solved
* long-distance dependencies -> not solved
---
![ApplicationFrameHost_t6cjfefnAF.png-250.8kB][5]
### 1. What Problems are Handled by Neural Language Models?
* similar words -> solved
* intervening words -> solved
* long-distance dependencies -> not solved
### 2. Training Tricks
* Shuffling the Training data: 因为SGD的梯度下降趋势受上一个例子影响
* Other Optimization Options
因为SGD梯度下降法太慢了,而且不够random,因此
* SGD with Momentum: 梯度下降法太慢了,这个可以2-5倍
* Adagrad: 可以调整学习速率,用梯度方差来测量
* **Adam**: 很快,稳定
* Many others: RMSProp
* Early Stopping, Learning Rate Decay
* 选择loss的最低点
* 需要使用Learning Rate Decay(又称为New Bob Strategy)
* Dropout
<center>![ApplicationFrameHost_MaYwyhvCBx.png-5.1kB][6]</center>
* randomly zero-out nodes in the hidden layer with probability p at **training time only**
* Because the number of nodes at training/test is different, scaling is necessary:
* standard dropout:
* inverted dropout:
* DropConnect(零化权重):
* Shuffling the Training data: 因为SGD的梯度下降趋势受上一个例子影响
* Other Optimization Options
因为SGD梯度下降法太慢了,而且不够random,因此
* SGD with Momentum: 梯度下降法太慢了,这个可以2-5倍
* Adagrad: 可以调整学习速率,用梯度方差来测量
* **Adam**: 很快,稳定
* Many others: RMSProp
* Early Stopping, Learning Rate Decay
* 选择loss的最低点
* 需要使用Learning Rate Decay(又称为New Bob Strategy)
* Dropout
<center>![ApplicationFrameHost_MaYwyhvCBx.png-5.1kB][6]</center>
* randomly zero-out nodes in the hidden layer with probability p at **training time only**
* Because the number of nodes at training/test is different, scaling is necessary:
* standard dropout:
* inverted dropout:
* DropConnect(零化权重):
### Efficiency Tricks: Mini-batching 批处理化
---
On modern hardware 10 operations of size 1 is much slower than 1 operation of size 10 (因为CPU和GPU都支持多线程)
![\[mini_batch\]][7]
---
On modern hardware 10 operations of size 1 is much slower than 1 operation of size 10 (因为CPU和GPU都支持多线程)
![\[mini_batch\]][7]
Tensorflow 和 Pytorch需要你针对 batch size 多加一个 dimension
#### Autobatching Usage
没听懂
没听懂
### A Case Study: Regularizing and Optimizing LSTM Language Models(Merity et al. 2017)
* uses LSTMS as a backbone
* A number of tricks to improve
* uses LSTMS as a backbone
* A number of tricks to improve
**设置 batch size 的技巧**
人们总是觉得 batch size 应该根据GPU尽可能地大,但这是不准确的。更大的batch size会使得最开始更新的很慢,所以你需要在开始的时候将batch size变小,而且batch size太大在开始的时候容易陷入局部最优。Google Brain的一项Paper证明,相比较于调整学习率,你更应该去调整batch size。
另一个小技巧是如果我想在最大的batch size等于32的GPU上使batch_size = 128,我可以等到四次批处理之后再开始更新参数,这样的效果是一样的
另一个小技巧是如果我想在最大的batch size等于32的GPU上使batch_size = 128,我可以等到四次批处理之后再开始更新参数,这样的效果是一样的
### 我自己的问题:
1. ~~什么是intervning words?~~
2. ~~什么是rank threshold?~~
3. Parameter Update 那里具体的更新是怎么样的?
4. 什么是Automatic Mini-batching?
5. ~~为什么要shuffle training data?~~
6. Dropout在test dataset的操作看不懂?
1. ~~什么是intervning words?~~
2. ~~什么是rank threshold?~~
3. Parameter Update 那里具体的更新是怎么样的?
4. 什么是Automatic Mini-batching?
5. ~~为什么要shuffle training data?~~
6. Dropout在test dataset的操作看不懂?
[1]: http://static.zybuluo.com/xuzhaoqing/u40075pw0mbbknfssg334itp/ApplicationFrameHost_3KLbZh5fM5.png
[2]: http://static.zybuluo.com/xuzhaoqing/82byufgi9ijt3nbkfmx51oxk/ApplicationFrameHost_7TdihjnEGj.png
[3]: http://static.zybuluo.com/xuzhaoqing/z6hcm21tl6f6ajt0hxx9aq4w/lookup.png
[4]: http://static.zybuluo.com/xuzhaoqing/iqe4c2bdas06wna0hwn8pcbc/ApplicationFrameHost_mjrJo4kTqV.png
[5]: http://static.zybuluo.com/xuzhaoqing/8a12cfck4k4epzhl0dewvgwy/ApplicationFrameHost_t6cjfefnAF.png
[6]: http://static.zybuluo.com/xuzhaoqing/utkybwqs4vu26330e5qfqq6g/ApplicationFrameHost_MaYwyhvCBx.png
[7]: http://static.zybuluo.com/xuzhaoqing/svjde9jntj6o4rkfzr5u4t0a/ApplicationFrameHost_CsWB9GpYY4.png
the difficult of NLP:
(1) what's the normal sentence?
(2) the past tense of verb
the feature expression
how to use BOW
what's the CBOW
why use Deep CBOW
the prediction of sentiment or sentiment classifier
CBOW
not nothing
Compution graph
forward propogation
static CG: tensorflow
synytatic CG: PyTorch
some examples of code
BOW
CBOW
Structure of this class
models of words
models of sentences
implements debug interpret of DL models
sequence to sequence model
structure prediction models
models of Tree and graph
advanced tech
models of knowledge and context
mutil-task/language learning
advanced search tech
老师会有一些课前阅读材料,也要阅读。


 客服1
客服1
 官方群
官方群