# (CMU CS 11-747 Week 2) Language Modeling 语言模型
标签(空格分隔): NLP CMU MOOC DeepLearning CS-11747
---
个人理解,语言模型的问题本质就是如何判定一句话是否通顺
## 1. Count-based Language Models 基于计数的语言模型
略去
### Problems and Solutions
* Cannot share strength among **similiar words**
Solution: class-based language models
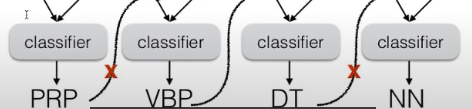
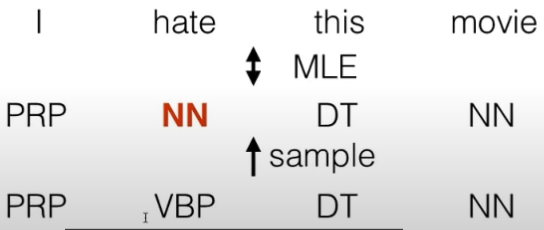
* Cannot condition on context with **intervening words**(上下文相同)
Dr. Jane Smith Dr. Gertrude Smith
Solution: skip-gram language models
* Cannot handle **long distance dependencies**
Solution: cache, trigger, topic, syntactic models
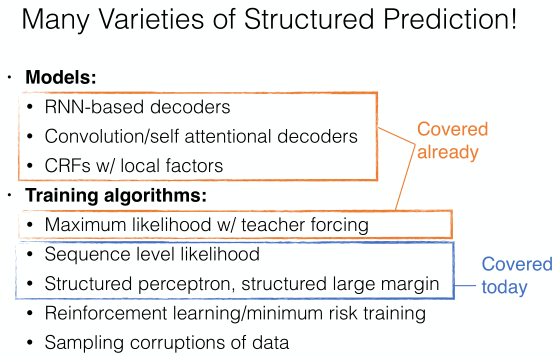
## 2. Featurized Log-linear Models
* Calculate features of the context 提取文本特征
* Based on the features, calculate probabilities 计算概率
* Optimize feature weights using gradient descent, etc. 利用梯度下降优化特征权重
![ApplicationFrameHost_3KLbZh5fM5.png-103.7kB][1]
之后再将得到的score利用`softmax`计算为概率
计算图可表示如下:
![ApplicationFrameHost_7TdihjnEGj.png-80.1kB][2]
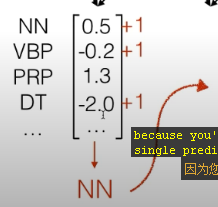
### Lookup 查找
![lookup.png-292.8kB][3]
两种方法:
* 第一种使用index, 时间复杂度为O(1), 更有效率更好
* 用 (vector * num\_of\_words) 与 one-hot vector 相乘,得到最终的word vector
### Training a model 训练模型
loss function 我们一般选取 `negative log likelihood`,这样选取的原因是算法更喜欢计算最小值(直接用导数值为0即可),因此对`p vector`中的最大值直接取`-log`即可,如下图所示:
![ApplicationFrameHost_mjrJo4kTqV.png-35.8kB][4]
### Parameter Update 参数更新
使用的是反向传播算法,计算的是$\frac{\partial l}{\partial \theta}$, **这里还不太懂**,使用SGD来优化的话,参数更新的方程式就是这样的:
$$\theta \leftarrow \theta - \alpha\frac{\partial l}{\partial \theta}$$
### Choosing a Vocabulary 选择词库
如果希望比较不同的模型,请确保它们的词库相同。当然,基于char和基于vocabulary的模型是可以放在一起比较的,因为基于char的模型它可以生成基于vocabulary的模型。
#### Unknown Words
一般应该设定在`word_freq`小于某值时(例如5),就将它设为`UNK`,因为这样可以显著减少词库个数,以及最后的权重矩阵大小。当然也k可以使用rank threshold, 使用自己定义的rank来排除掉最后rank低的单词,将他们定义为`UNK`。
## What Problems are Handled?
* similar words -> Not solved!
* intervening words -> solved!
* handle long-distance dependencies -> Not solved!
---
**Linear Models Can't learn Feature Combinations**
farmers eat steak -> high farmers eat hay -> low
cows eat steak -> low cows eat hay -> high
What could we do?
* Remember combinations as features (N-gram) -> 导致内存爆炸
* Neural Nets
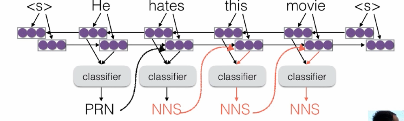
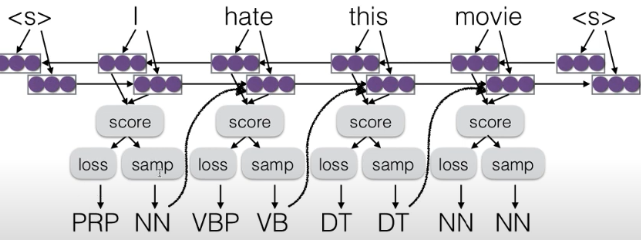
## 3.Neural Language Models
---
![ApplicationFrameHost_t6cjfefnAF.png-250.8kB][5]
### 1. What Problems are Handled by Neural Language Models?
* similar words -> solved
* intervening words -> solved
* long-distance dependencies -> not solved
### 2. Training Tricks
* Shuffling the Training data: 因为SGD的梯度下降趋势受上一个例子影响
* Other Optimization Options
因为SGD梯度下降法太慢了,而且不够random,因此
* SGD with Momentum: 梯度下降法太慢了,这个可以2-5倍
* Adagrad: 可以调整学习速率,用梯度方差来测量
* **Adam**: 很快,稳定
* Many others: RMSProp
* Early Stopping, Learning Rate Decay
* 选择loss的最低点
* 需要使用Learning Rate Decay(又称为New Bob Strategy)
* Dropout
<center>![ApplicationFrameHost_MaYwyhvCBx.png-5.1kB][6]</center>
* randomly zero-out nodes in the hidden layer with probability p at **training time only**
* Because the number of nodes at training/test is different, scaling is necessary:
* standard dropout:
* inverted dropout:
* DropConnect(零化权重):
### Efficiency Tricks: Mini-batching 批处理化
---
On modern hardware 10 operations of size 1 is much slower than 1 operation of size 10 (因为CPU和GPU都支持多线程)
![\[mini_batch\]][7]
Tensorflow 和 Pytorch需要你针对 batch size 多加一个 dimension
#### Autobatching Usage
没听懂
### A Case Study: Regularizing and Optimizing LSTM Language Models(Merity et al. 2017)
* uses LSTMS as a backbone
* A number of tricks to improve
**设置 batch size 的技巧**
人们总是觉得 batch size 应该根据GPU尽可能地大,但这是不准确的。更大的batch size会使得最开始更新的很慢,所以你需要在开始的时候将batch size变小,而且batch size太大在开始的时候容易陷入局部最优。Google Brain的一项Paper证明,相比较于调整学习率,你更应该去调整batch size。
另一个小技巧是如果我想在最大的batch size等于32的GPU上使batch_size = 128,我可以等到四次批处理之后再开始更新参数,这样的效果是一样的
### 我自己的问题:
1. ~~什么是intervning words?~~
2. ~~什么是rank threshold?~~
3. Parameter Update 那里具体的更新是怎么样的?
4. 什么是Automatic Mini-batching?
5. ~~为什么要shuffle training data?~~
6. Dropout在test dataset的操作看不懂?
[1]: http://static.zybuluo.com/xuzhaoqing/u40075pw0mbbknfssg334itp/ApplicationFrameHost_3KLbZh5fM5.png
[2]: http://static.zybuluo.com/xuzhaoqing/82byufgi9ijt3nbkfmx51oxk/ApplicationFrameHost_7TdihjnEGj.png
[3]: http://static.zybuluo.com/xuzhaoqing/z6hcm21tl6f6ajt0hxx9aq4w/lookup.png
[4]: http://static.zybuluo.com/xuzhaoqing/iqe4c2bdas06wna0hwn8pcbc/ApplicationFrameHost_mjrJo4kTqV.png
[5]: http://static.zybuluo.com/xuzhaoqing/8a12cfck4k4epzhl0dewvgwy/ApplicationFrameHost_t6cjfefnAF.png
[6]: http://static.zybuluo.com/xuzhaoqing/utkybwqs4vu26330e5qfqq6g/ApplicationFrameHost_MaYwyhvCBx.png
[7]: http://static.zybuluo.com/xuzhaoqing/svjde9jntj6o4rkfzr5u4t0a/ApplicationFrameHost_CsWB9GpYY4.png



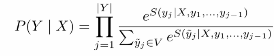
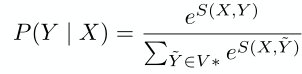



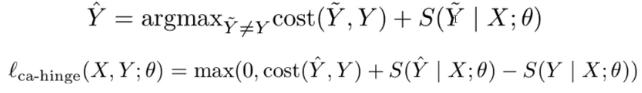
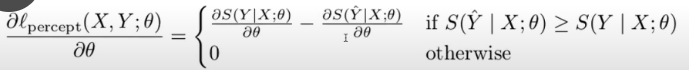


 客服1
客服1
 官方群
官方群