


注:本文笔记根据2020年课程所写,但很多还不明白,新版框架更清晰,但没有讲local bias,可能是放在前面几节课讲,先放到这里以后再开
STRUCTURE PREDICTION
- 一种问题
- 等长序列标注任务
- 不等长序列生成任务
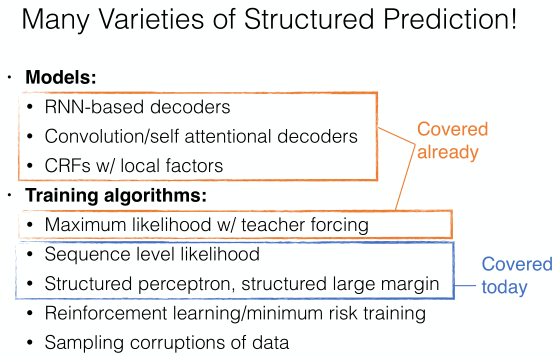
- sequence maxinum likehood 两种normal的不同差异
- local normalization
- 单个单词可能性的乘积
- 优点速度快
- 但容易陷入错误的解,特别是进入到选项比较少的情况新版本删掉
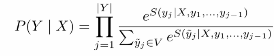
- global normalization 能量模型
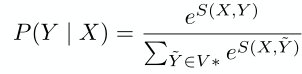
- 整个句子的概率
- 最优解但softmax速度慢
- 结构化模型用动态规划 crf cfg
- partition function配分函数sampling
- sampling:采样k个samples做配分函数
- 无偏估计
- 高方差
- 预测用的:beam search k个最好的假设
- 我的想法:这步好像避免求概率,score就可以
- 有偏估计
- 低方差
- sampling:采样k个samples做配分函数
- local normalization
- unnormal 模型
- 什么时候需要normal
- 下游需要知道你这个预测的准确率,可能性的时候
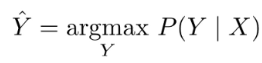
- 额外知识:概率模型校准
- 输出的概率和输出的可信度成直线正比 538
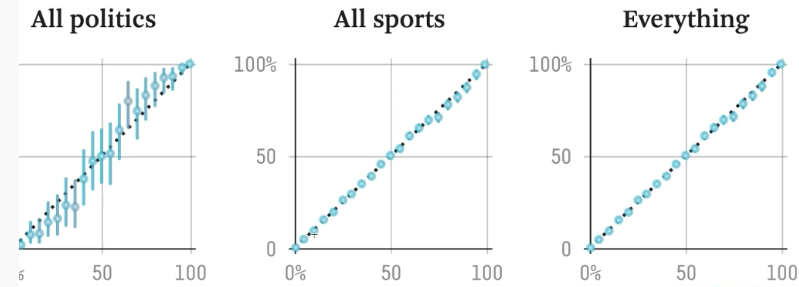
- 神经网络输出很高,但置信度不是很大
- 输出的概率和输出的可信度成直线正比 538
- 下游需要知道你这个预测的准确率,可能性的时候
- 推断的时候我们不需要知道概率
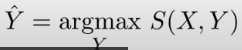
- 什么时候需要normal
- 非结构化方法:重复的multi classify
- independent classification

- 有一篇论文采用这种独立的分类对序列化模型crf做模型蒸馏,速度更快
- 不考虑输出信息的bilstm不算结构预测
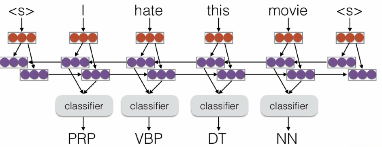
- 但我觉得内部信息有整体结构信息流动
- independent classification
- 结构化预测:利用信息和输出的结构信息
- 会帮助选出整体可能性最好的结果,高效
- 结构化感知机 structured perceptron
- loss
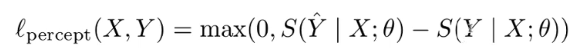
- 对比

- 我自己的理解softmax是一种梯度的分配,更新所有样本,相当于全局的global loss
- structured training pre-training
- 可以先用概率模型 更新所有样本,再用structure更新一个样本,避免exposure bias
- margin hinge loss
- svm
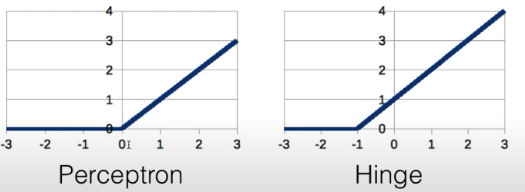

- 这里提了一点:hinge损失会找到中间平衡值
- 而交叉熵不会对负样本做出惩罚,会更偏向正样本
- Cross-Entropy Loss Leads To Poor Margins
https://openreview.net/forum?id=ByfbnsA9Km
- Cross-Entropy Loss Leads To Poor Margins
- svm
- cost augmented hinge
- 错误的代价是不同的
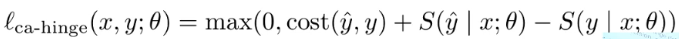
- costs over sequences
- zero-one loss
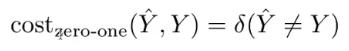
- hamming loss
- 一个元素一个错误
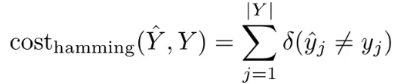
- 一个元素一个错误
- other losses
- edit distance 1-bleu
- zero-one loss
- 错误的代价是不同的
- structured hinge loss
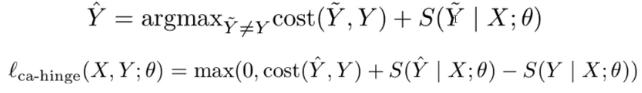
- 这里可能还是对训练说的,推测时我们不知道目标Y
- hamming loss
- 训练中损失+1,增加了一个margin,针对 exposure bias
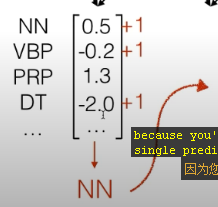
- 训练中损失+1,增加了一个margin,针对 exposure bias
- 对比
- 更新
- loss
- exposure bias
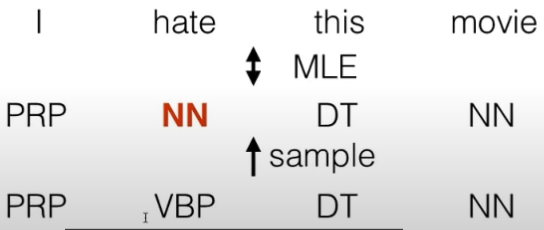
- 问题:teacher forceing
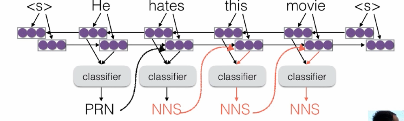
- 我们一直再给序列输入前一个正确的输出,这样实际中模型会严重依赖前一个输出,如果实际中预测错误,会严重影响后面的预测
- 类似bert训练中的mask不在实际预测中出现
- 解决办法
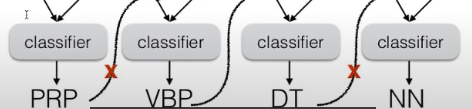
- 感知机算法
- 忍受exposure bias 的pretrain 更有效率
- more complicated algorithm : cost hinge loss 的结构化感知机fine tune
- sample mistakes in training
- dagger 不使用预测的输出
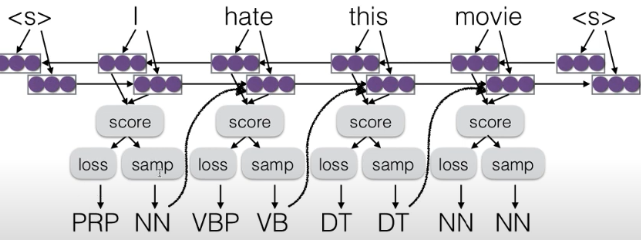
- scheduled sampling pretrain
- 一开始不采样错误,后来引入错误
- 用于语音识别非常好,因为你不确定你听到的到底是什么
- scheduled sampling pretrain
- dynamic oracle
- 用于机器翻译
- dagger 不使用预测的输出
- drop out inputs
- 不太依靠上文输出
- 更多的选择 :corrupt training data
- reward augmented maximum likelihood
- 制造错误样本输入 好处不学习0 学习错误的 更现实
- sample 概率与cost成反比,更愿意sample cost为0的词
- 感知机算法
- 问题:teacher forceing


 客服1
客服1
 官方群
官方群