笔记:深度理解强化学习
主讲:王湛
第一课:强化学习初步介绍
这节课程有两部分:
一、课程简介
二、通过实际例子介绍传统机器学习(有监督和无监督)能做什么以及不能做什么,强化学习能做什么。
一、课程简介
1、强化学习能做什么?
经典的例子,如围棋(AlphaGo)、机器人(Boston robot)、游戏(DOTA)等。
2、预备知识
概率论、矩阵分析、优化理论
Python基础
机器学习、深度学习(选学)
强化学习是ML的一种,所以即使没有学过其他的知识也可以学习这个课程。
3、能够学到什么?
- RL基本算法原理和数学推导
- 实战设计RL算法训练agent
- 阅读文献自学最新的RL算法的能力
二、强化学习能做什么:
1、传统机器学习能做什么?
有监督学习:回归任务、分类任务
无监督学习(没有标签):K-means聚类(应用:超像素分割)
2、传统机器学习不能做什么?
机器人、围棋。
无监督学习由于智能对现有数据做一定意义的聚类,显然不适用于这些任务。
监督学习由于需要大量的人工标签来构建相当庞大的训练集,成本太高并不适用。
3、强化学习能做什么
"If one of the goals that we work for here is Al then it is at the core of that. Reinforcement Learning is a very general framework for learning sequential decision making tasks. And Deep Learning, on the other hand, is of course the best set of algorithms we have to learn representations. And combinations of these two different models is the best answer so far we have in terms of learning very good state representations of very challenging tasks that ore not just for solving toy domains but actually to solve challenging real world problems."
--David Sliver
简单来说,即强化学习是一个学习序列决策过程的一般框架。
一个大胆的假设:任何问题如果能够简化成一个决策问题,就可以用强化学习来解答。(这种思想非常重要)
应用案例1:围棋、吃豆子游戏。
应用案例2:强化学习还可以完成管理和控制的任务。例如计算机集群的资源管理、交通灯控制,实现资源实时、动态的分配和利用。
应用案例3:机器人动作。
应用案例4:化学反应的优化。配比、催化剂、温度等。研发新的有机物。
应用案例5:淘宝通过用户基本信息、购买记录等的个性化推荐。
4、结论
强化学习非常广,除了学好强化学习算法,更重要的是学会强化学习的思考方式,能够在日常问题的解决中合理利用。
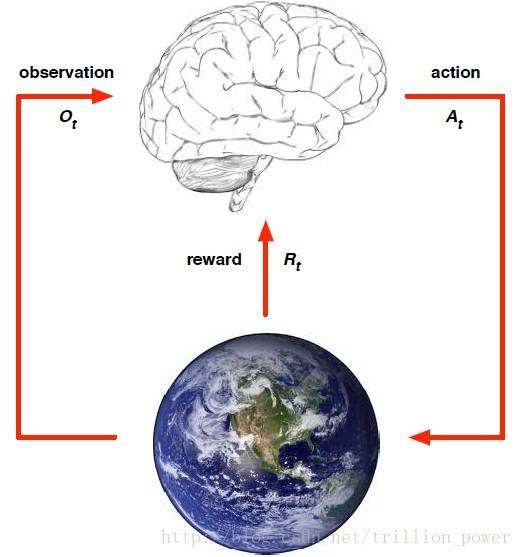
强化学习的一般框架:
下一节:强化学习的基本要素和概念



 客服1
客服1
 官方群
官方群