


强化学习的关键要素主要有:环境(Environment)、激励(reward)、动作(action)和状态(state)。有了这些要素后,我们就可以建立一个强化学习模型。强化学习解决的问题是:针对一个具体问题得到一个最有的策略,使得在该策略下获得的激励最大。所谓的策略其实就是一系列的动作,也就是序列数据。
(策略是状态到动作的映射,分为确定策略与随机策略。确定策略就是某一状态下的确定动作,随机策略以概率来描述,即某一状态下执行某一动作的概率。)
强化学习可以用下图来刻画:都是要先从要完成的任务提取一个环境,从中抽象出状态、动作以及执行此动作所接受的瞬时激励。
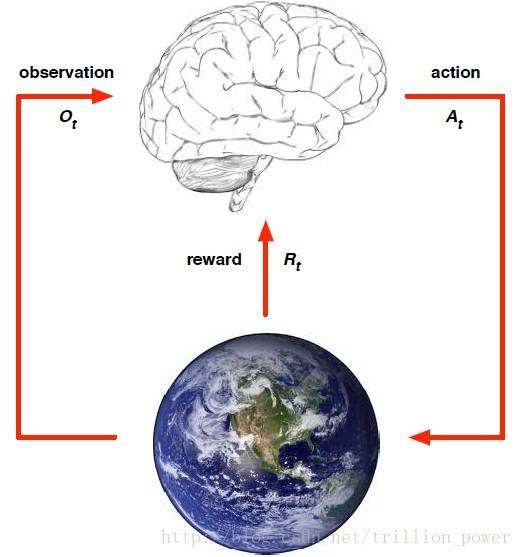
强化学习与传统机器学习的不同之处
- 训练数据没有类标,只有激励信息,本质上来说,激励信息也可以看作是一种类标。
- 反馈可能有延时,无法立即返回
- 输入数据是序列数据。
- 智能体的动作会影响到后续的数据。
直观来看强化学习
- 一些棋类运动,Alpha-Go、Alpha-Zero等
- 波士顿机器人:一个综合智能体的机器人
- 训练智能体玩游戏
需要先修的内容
- 数学方面:概率、矩阵、优化
- 开发方面:Python基础
- 其他:机器学习与深度学习
强化学习的应用
- 强化学习可适用于序列决策的任务,比如波士顿机器人在前进中的控制,围棋博弈的过程等。一般来说,只要能将一个问题简化成一个决策问题,基本上可以使用强化学习来解决此问题。
- 在资源调度管理中,也可以使用强化学习算来进行动态分配。
- 在智慧城市中也有应用,比如交通灯的控制问题:使用强化学习,通过智能体,根据实际情况动态的改变交通灯时长的控制。
- 强化学习现在应用到了化学领域,比如:原料配比、催化剂的使用,温度的选择(是否需要加热等)。
- 淘宝个性化推荐也用了强化学习:建立一个agent,对其设定一些条件,比如年龄,爱好倾向等,然后通过强化学习进行推荐,并根据数据来对推荐结果进行反馈。
 客服1
客服1
 官方群
官方群