



损失函数
L = 1/N * L(f, yi)
¥
支付方式
请使用微信扫一扫 扫描二维码支付
请使用支付宝扫一扫 扫描二维码支付
损失函数
L = 1/N * L(f, yi)
1.线性分类:它有助于我们建立整个神经网络和整个卷积网络,就像巨型网络的基础模块
2.卷积神经网络只关注图像,而循环神经网络只关注语言,我们可以把这两个网络放在一起,再将其一块训练,最终得到一个很厉害的系统
3.线性分类器:它是参数模型中最简单的例子 f(x,W)我们通常把输入数据写为x,参数设置或是权重通常叫做W,有时也叫θ
4.在一个参数化的方法中,我们将总结我们对训练数据的认识并把所有的知识都用到这些参数W中,在测试的时候我们不再需要实际的训练数据,我们可以把它扔掉,我们在测试时,只需要这些参数W,这使我们的模型更有效率,所以在深度学习中,整个描述都是关于函数F正确的结构,你可以发挥你的想象来编写不同的函数形式,用不同的,复杂的方式组合权重和数据,这些可以对应于不同的神经网络体系结构,但将它们相乘就是最简单的结合方式,这就是一个线性分类器
4.每个线性分类器只学习一个单独的模板,如果这个类别出现了某种类型的变体,那么它将尝试求取所有不同变体所有那些不同变现的平均值,并且只使用一个单独的模板来识别其中的每一个类别
5.小结:本节课程我们讨论了,线性分类器对应的函数形式,我们看到这个矩阵向量相乘的函数形式对应于模板匹配和在数据集中为每一个类别学习一个单独的模板,一旦我们有了这个训练矩阵,实际上你可以使用它得到任何新的训练样本的得分,但在课程中没有讲述如何给你的数据集选择一个正确的权重
1.线性分类可以解释为每个种类的学习模板,矩阵W里的每一行都对应着一个分类模板,如果我们能解开这些行的值,那么每一行又分别对应一些权重,每个图像像素值和对应那个类别的一些权重,将这行分解回图像的大小
2.可以用一个函数把W当做输入,然后看一下得分,定量的估计W的好坏,这个函数被称为损失函数(其实就是选择好的权重W)
3.所谓的损失函数,比方来说,有一些训练数据集x,y,通常我们说有N个样本,其中x是算法的输入,在图片分类问题里,x其实是图片每个像素点所构成的数据集,y是你希望算法预测出来的东西,我们通常称之为标签或目标,标签y是一个在1到10之间的整数,这个整数表明对每个图片x哪个类是正确的,我们把损失函数记做L_i
4.我们有了这个关于X的预测函数后,这个函数就是通过样本x和权重矩阵W给出y的预测,在图像分类问题里,就是给出10个数字中的一个,我们可以给出一个损失函数L_i的定义,通过函数f,给出预测的分数和真实的目标或者说标签y,可以定量的描述训练样本预测的好不好,最终L是N个样本损失函数的总和的平均值
5.除了真实的分类Y_i以外,对所有的分类Y都做加和,也就是说我们在所有错误的分类上做和,比较正确分类的分数和错误分类的分数,如果正确分类的分数比错误分类的分数高,比错误分类的分数高出某个安全的边距,那么损失为0,接下来把图片对每个错误分类的损失加起来,就可以得到数据集中这个样本的最终损失,S是通过分类器预测出来的类的分数
6.S_Yi表示训练集第i个样本的真实分类的分数
7.分类器如何在这些都是0值的损失函数间做出选择呢? 机器学习的重点是:我们使用训练数据来找到一些分类器,然后我们将这个东西应用于测试数据,所以我们并不关心训练集的表现,我们关心的是这个分类器的测试数据 向损失函数里加入正则化,鼓励模型以某种方式选择更简单的W,这里所谓的简约取决于任务的规模和模型的种类 这样损失函数就有了两个项,数据丢失项和正则项,这里有一些超参数γ用来平衡这两个项
8.正则化 实际上有很多不同的类型正在实践中使用的正则化,最常见的可能就是L2正则化或权值衰减,L2正则化的理念实际上是对这个权重向量的欧式范数进行惩罚。正则化的宏观理念就是:你对你的模型做的任何事,也就是种种所谓的处罚,主要目的是为了减轻模型的复杂度,而不是去试图拟合数据 L1度量复杂度的方式有可能是非0元素的个数,而L2更多考虑的是W的整体分布,所有元素具有较小的复杂性,贝叶斯分类器就可以用L2正则化得到非常好的解释 我的理解:加入正则化就是为了让曲线更加贴近直线,为了使我们的权重系数W变化从而取得最好的分类结果https://www.zhihu.com/question/52398145 有详细解释损失函数。
9.softmax loss softmax直白来说就是将原来输出是3,1,-3的分数通过softmax函数一作用(先指数化,在归一化),就映射成为(0,1)的值,而这些值的累和为1(满足概率的性质),那么我们就可以将它理解成概率,在最后选取输出结点的时候,我们就可以选取概率最大(也就是值对应最大的)结点,作为我们的预测目标!我们用softmax loss对分数进行转化处理并得到正确的类别的损失函数是-log P
计算机视觉的发展历史:
计算机视觉的发展历史:
动物进化出眼睛;生物视觉-》机器视觉-》照相机;
生物学家开始研究视觉的机理,Hubel & Wiesel,1959,他们的问题是:哺乳动物的视觉处理机制是怎样的呢?他们讲电极插进主要控制猫视觉的后脑上的初级视觉皮层,然后观察,何种刺激会引起视觉皮层神经元的反应。他们发现猫的大脑的初级视觉皮层有各种各样的细胞,其中最重要的细胞是当它们朝着某个特定的方向运动的时候,对面向边缘产生回应的细胞。当然还有更加复杂的细胞,但是总的来说,它们发现视觉初级是始于视觉世界的简单结构,面向边缘,沿着视觉处理途径的移动,信息也在变化,大脑建立了复杂的视觉信息,直到它可以识别更为复杂的视觉世界。
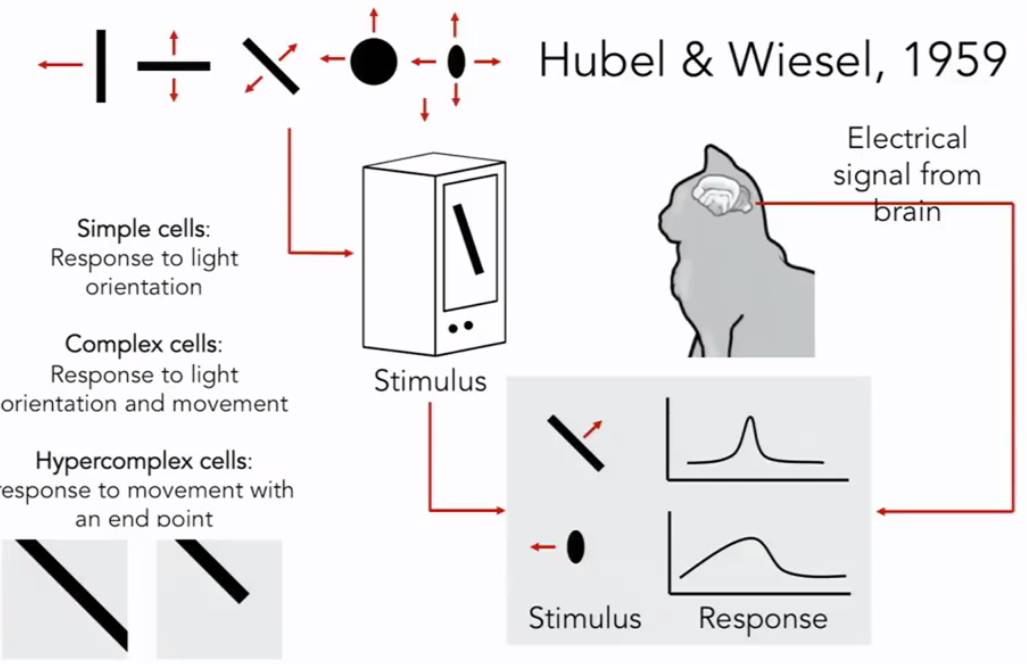
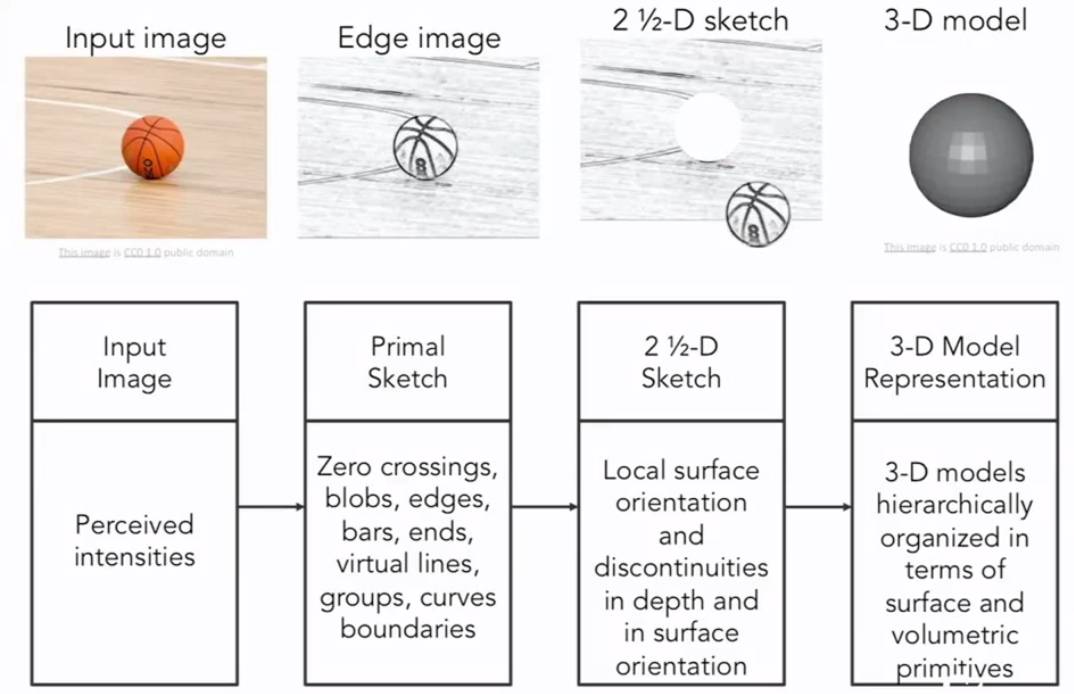
计算机视觉的历史是从60年代初开始的,Block World 是由Larry Roberts出版的一部作品,被广泛地称为计算机视觉的第一篇博士论文,其中视觉世界被简化为简单的额几何形状,目的是能够识别它们,重建这些形状是什么。1966年MIT的暑期视觉项目,目的是为了构建视觉系统的重要组成部分。David Marr,一个MIT 视觉科学家提出了使得计算机识别视觉世界的算法,他指出,为了获取视觉世界完整的3D图像,需要经历几个阶段:第一个阶段是原始草图,大部分边缘、端点和虚拟线条,这是受到了神经科学家的启发,Hubel &Wiesel 告诉我们视觉处理的早期阶段有很多关于像边缘的简单结构;第二阶段是David Marr 所说的“2.5维草图”我们开始将表面、深度信息、不同的层次以及视觉场景的不连续性拼凑在一起的;最后一个阶段是将所有的内容放在一起,组成一个3D模型。这是一个非常理想化的思想过程,这种思维方式实际上已经在计算机视觉领域影响了几十年。这也是一个非常直观的方式,并考虑如何解构视觉信息。
七十年代另外一个非常重要的工作(Brooks&Binford,1979 Fischler & Elschlager 1973),这个时候他们提出了一个问题,我们如何越过简单的块状世界,开始识别和表示现实世界的对象。70年代是一个没有数据可用的时代,计算机的速度很慢,计算机科学家开始思考如何识别和表示对象,在斯坦福大学的帕洛阿尔托以及斯里兰卡提出了类似的想法,一个被称为广义圆柱体,一个被称为圆形结构,他们的基本思想是每个对象都是由简单的几何图单位组成,任何一种表示的方法就是讲物体的复杂结构,简约成一个集合体,有更简单的形状和几何结构,这些研究已经影响了很长很长的一段时间。
80年代,David Lowe思考如何重建或者识别由简单的物体结构组成的视觉空间,他尝试识别剃须刀,通过先和边缘进行构建,其中大部分都是直线以及直线之间的组合。那个时候由于样本小,物体识别是很难的。
如果物体识别太难了,那么我们首先要做的是目标分割,这个任务就是把一张图片中的像素点归类到有意义的区域,我们可能不知道这些像素点组合到一起是一个人型,但是我们可以把这些属于这人的像素点从背景中抠出来,这个过程就叫做图像分割,这项工作是由Berkeley的 Jitendra Malik和他的学生Jianbo Shi 所完成的。他们用一个图论算法对图像进行分割,还有另外一个问题,先于其他计算机视觉问题有进展,也就是面部检测,脸部是人类最重要的部位之一。
1999-2000年机器学习技术,特别是统计机器学习方法,开始加速发展,出现了很多方法:支持向量机模型,boosting方法,图模型。有一种工作做出了很多贡献,技术使用AdaBoost 算法进行实时面部检测,由Paul Viola和Michal Jones 完成。在他们发表论文后的第五年,也就是2006年,富士康推出了第一个具有实时面部识别的照相机。这是从基础科学研究到实际应用的一个快速转化,关于如何才能能够做到更好的目标识别,这是一个我们可以继续研究的领域。从90年代末到2000年的前十年有一个非常有影响力的思想方法是基于特征的目标识别,这里有一个影响深远的工作,由 David Lowe完成,叫做SIFT特征,思路就是去匹配整个目标。例如这里有一个stop标识去匹配另外一个stop标识是非常困难的,因为有很多变化的因素,比如相机的角度、遮挡、视角、光线以及目标自身的内在变化,但是可以得到一些启发,通过观察目标的某些部分,某些特征是能够在变化中保持不变性,所以目标识别的首要任务是在目标上确认这些关键的特征,然后把这些特征与相似的特征进行匹配,它比匹配整个目标要容易得多。我们这个领域另外一些进展是识别整幅图的场景,有一个算法叫空间金字塔匹配,背后的思想是图片里面有各种特征,这些特征可以告诉我们这是哪种场景,到底是风景还是厨房,或者是高速公路等等 。这个算法从图片的各部分,各个像素抽取特征,并把他们放在一起,作为一个特征描述符,然后在特征描述符上做一个支持向量机。有个在人类认知方面很类似的工作正处于风头浪尖。有些工作是把这些特征放在一起之后,研究如果在实际图片中合理地设计人体姿态和辨认人体姿态,这方面一个工作被称为方向梯度直方图;另外一个被称为可变形部件模型。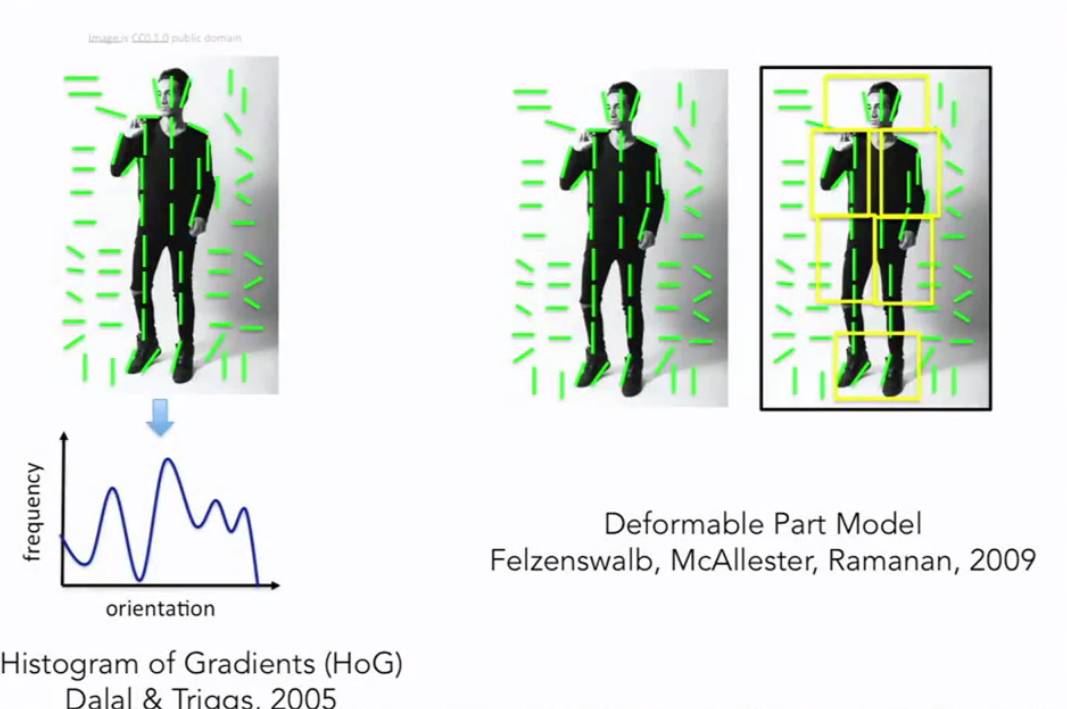
可以看到我们从60年代、70年代、80年代一步步走到20世纪,有一件事情一直在变化,就是图片的质量,随着互联网的发展,随着数码相机的发展,计算机视觉的研究也能拥有更好的数据了,计算机视觉在21世纪早期提出了一个非常重要的基本问题,我们一直在目标识别,但是直到21世纪的早期,我们才开始真正拥有标注的数据集,能供我们衡量在弥补识别方面取得的成果,其中最具有影响力的标记数据集之一叫PASCAL Visual Object Challenge 这个数据集由20个类别的图片,数据集中的每个种类都有成千上万张图片,
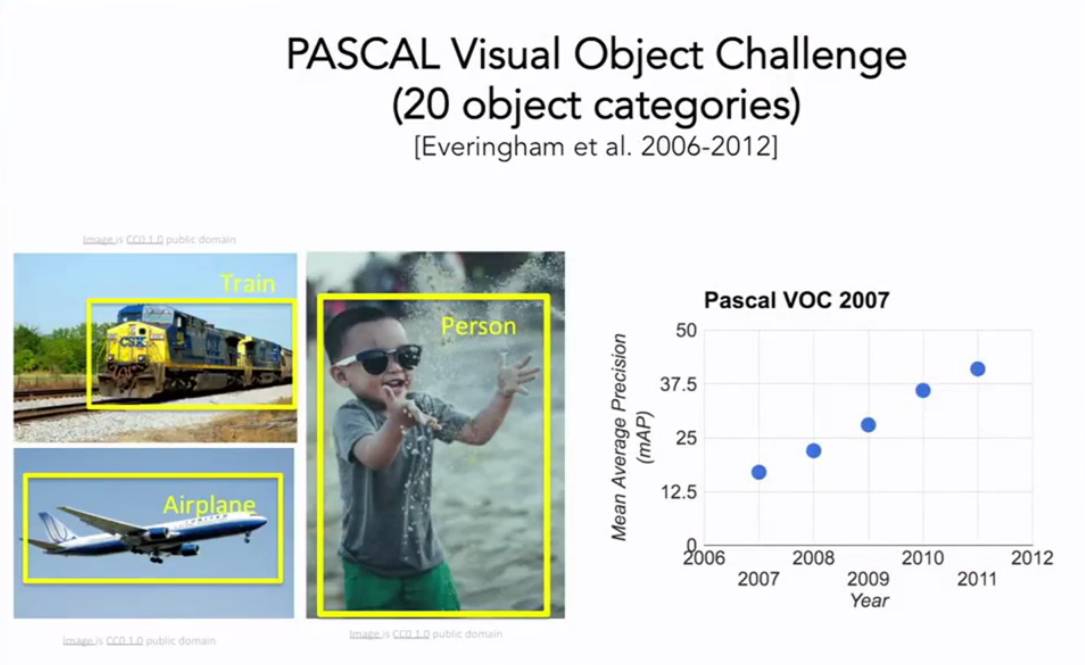
现场不同的团队开发算法来和数据测试集做对抗训练,来看有毛毛雨优化,这里有一张图表列举了从2007年到2012年在基准数据集上检测图像中的20中目标的检测效果,可以看到在稳步提升。在差不多时候,普林斯顿和斯坦福中的一批人开始,向我们或者说我们这个领域提出了一个更加困难的问题,我们是否具备了识别真实世界中的每一个舞台的能力,或者说大部分物体。这个问题是由机器学习中的一个现象驱动的,就是大部分的机器学习算法,无论是图模型,还是支持向量机或者是AdaBoost都可能会在训练过程中过拟合,部分原因是可视化的数据非常复杂,我们的模型的维数就很高,参数量就很大,输入是高维的模型,则还有一堆参数需要调优,当我们的训练数据量不够时,很快就产生了过拟合的现象,这样我们就无法很好地泛化,因此即使有两方面的动力,一是我们单纯地想识别自然世界中的万物,二是要回归机器学习克服机器学习中的瓶颈问题,过拟合问题。 LIfeifei开展了一个叫ImageNet的项目,汇集所有能够找到的图片,包含世界万物,组建一个尽可能大的数据集,用一个称为WorldNet的字典来排序,这个字典里有上万个物体类别,用亚马逊土耳其机器人平台进行排序清洗数据,给每张图片打上标签,最终的结果是一个ImageNet,最后由将近500万甚至4000万多的图片,分成22000类的舞台或者场景,这是一个巨大的,很有可能是由当时AI领域最大的数据集,它将目标检测算法的发展推到了一个新的高度。从2009年开始,ImageNet团队组织了一场国际比赛,叫做ImageNet大规模视觉识别竞赛,这是一个筛选更严格的测试集,总共140万的目标图像有1000种目标类别,分别识别来测试计算机视觉算法。2012年卷积神经网络算法击败了所有其他的算法。CNN模型展现了强大的能量。
图像分类:数据驱动方法
图像分类任务是计算机视觉中的主要任务,当你做图像分类的时候分类系统接收了一些输入图像,比如可爱的猫,并且系统已经清楚了一些确定了分类或者标签的集合,这些标签可能是一只狗狗或者一只猫咪,也有可能是一辆卡车,还有一些固定类别的标签集合,那么计算机的工作就是看图片,但是它肯定没有人对猫的那样一种概念,电脑看到的只是一些像素,所以对于计算机来说这是一个巨大的数字矩阵,很难从中提取出猫的特性,我们把这个称为语义鸿沟。对于猫咪的概念或者它的标签是我们赋予特性的一个语义标签,一个猫的语义标签和计算机实际上看到的像素值之间有着巨大的差距。一旦图片发生了微妙的变化,这将导致像素网路整个发生变化,虽然两个矩阵中的数据完全不同,但是它们仍然都是代表猫,因此我们的算法需要对这些变化鲁棒。还不仅仅是视角的问题,还有光照条件不同的问题,目标对象还有变形的问题,还有遮挡的问题以及类内差异的问题,我们的算法应该是在这些条件下都是鲁棒的。
我们可以用Python写一个图像分类器,输入是图像,输出为图像的标签。
比如:
def classify_image(image):
return class_label
目前我们并没有直截了当的图像识别算法。
目前有一些硬编码的规则来识别不同的动物,我们都知道猫有耳朵、眼睛、嘴巴、鼻子,根据Hubel &Wiesel的研究,我们了解到边缘对于视觉识别是非常重要的,所以我们可以尝试计算图像的边缘,然后把边、角等各种形状分类好,比如有三条线是这样相交的,那这就可能是一个角点,比如猫耳朵有这样那样的角因此我们可以写一些规则来识别这些猫。但是实际上这些算法是不好的,容易出错。其次,如果我们相对另外一种对象进行分类,比如除了猫,我们需要识别其他的动物,就需要从头开始。

我们需要一种可以推演的方法,那就是数据驱动的方法。
我们不写具体的分类规则来识别一只猫或者鱼,我们从网上抓取大量猫的图片的数据集,一旦我们有了数据集,我们训练机器来分类这些图片,机器会去收集所有的数据,用某种方式总结,然后生成一个模型,总结出识别出这些不同类的对象的核心知识要素,然后我们用这些模型来是识别新的图片。因此我们的借口变成了这样:
写一个函数,不仅仅是输入图片,然后识别他是一只猫,我们会有两个函数,一个是训练函数,这函数接收图片和标签,然后输出模型;
另外一个函数输入新图片,然后输出标签。前一个模型为训练模型,后一个为预测模型。
我们用一定的规则来比对一组图片,
比如L1 distance ,将两幅图片的像素相减,求这些差的绝对值之和。

完整的Nearest NeighborPython 代码:
import numpy as np #进行向量运算
class NearestNeighbor:
def __init__(self):
pass
def train(self,x,y):
""" X is N * D where each row is an example . Y is 1-dimension of size N """
#近邻算法在训练阶段只是简单得记住训练数据
def predit(self,x):
""" X is N * D where each row is an example we wish to predict label for """
num_test = x,shape[0]
#保存输入输出的格式一致
Ypred = np.zeros(num_test,dtype=self.ytr.dtype)
for i in xrange(num_test):
#循环遍历每一个测试数据
distance = np.sum(np.abs(self.xtr-x[i,:}),asix=1)
min_index = np.argmin(diatances)
Ypred[i] = self.ytr[min_index]
return Ypred
注意:因为近邻算法在训练阶段只是简单地记住了训练图片,所以它的时间复杂度是0(1),但是测试阶段就是有一个将训练数据与测试数据对比的过程,其时间复杂度就是O(N)。与卷积神经网络不同,卷积神经网络在训练阶段花费的时间很长,在测试阶段就很快。
K最近邻(k-Nearest Neighbour,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
用官方的话来说,所谓K近邻算法,即是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例(也就是上面所说的K个邻居), 这K个实例的多数属于某个类,就把该输入实例分类到这个类中。 K值越大,边界越平滑。
图像分类:K最近邻算法
K最近邻(k-Nearest Neighbour,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
用官方的话来说,所谓K近邻算法,即是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例(也就是上面所说的K个邻居), 这K个实例的多数属于某个类,就把该输入实例分类到这个类中。 K值越大,边界越平滑。
注意:KNN在图像分类中表现不好。
一旦我们用KNN来区分图片的时候,得先找到计算图片差异的方法,比如L1距离,这个计算的是两幅图片所有像素之间的差的绝对值的总和,此计算方法对坐标比较依赖,一旦改变了坐标,这个值就不一样了,以此不是很可靠;但是另外一种常见的选择是L2距离,也就是欧式距离,求的是图片的所有像素的差的平方和的平方根,这个值就不再依赖于坐标系,比较可靠了。如果你输入的特征向量,如果向量中的一些值有一些重要的意义,那么也许L1可能更加合适;但是如果它只是某个空间中的一个通用向量,而你不知道其中的不同的元素,你不知道它们实际上代表的含义,那么L2可能更加自然一些。我们可以使用不同的距离度量将KNN分类器泛化到许多不同的数据类型上,不仅仅是向量和图像,比如想对文本进行分类,那么你唯一需要做的就是对KNN指定一个距离函数,这个函数可以测量两段话或者两句话或者类似的东西之间的距离。因此,简单地通过指定不同的距离度量,我们便可以很好地应用这个算法,在基本上任何类型的数据上,尽管这是一种简单的算法,但是总的来说,当你研究一个新的问题的时候,尝试它是一件很好的事情。

在几何上,我们使用不同的记录度量的时候,会出现不同的决策边界。使用L1度量时,这些决策边界倾向于跟随坐标轴,而根据L2度量的决策边界就自然很多。

当我们选择不同的K值以及不同的距离度量的时候,这个决策边界就不同,那么我们怎么根据自己的数据来选择这些超参数呢?超参数就是不能通过训练数据而得到的参数。我们要提前为算法做出的选择。很多人的做法就是根据自己的数据,选择不同的超参数,然后进行训练,看哪一个值是最好的。但是其实这个一种非常糟糕的算法,比如,在之前的KNN算法中,假如K=1,我们总能完美分类训练数据,所以如果我们采用这一策略总是选择K=1,但是如之前的案例所见的,在实践中让K取更大的值,尽管会在训练集中分错个别数据,但对于在训练集中出现过的数据分类性能更佳。归根到底在机器学习中我们关心的不是尽可能拟合训练集,而是要让我们的分类器、我们的算法,在训练集之外的未知数据上表现得更好。
还有一种想法就是把所有的数据,分成训练数据和测试数据两个部分,然后在训练集上使用不同的超参数来训练算法,然后将训练好的分类器用在测试集上。再选择一组在测试集上表现最好的超参数。这种做法同样很糟糕,因为机器学习系统的目的是让我们理解算法表现究竟如何,所以测试集的目的,是给我们一种预估方法。如果采用这种使用不同的超参数训练不同算法的策略,然后选择在测试集上表现最好的超参数,那么有可能我们选择了一直超参数只是让我们的算法在这组测试集上表现良好,但是这组测试集的表现,无法代表在全新的未见过的数据上的表现,所以再说一遍不要这么做,这个想法很糟糕。更常见的额做法是将数据分成三部分,大部分作为训练集,然后分成一部分作为验证集,剩下的一部分作为测试集。我们通常所做的就是在训练集上用不同的超参来训练算法,在验证集上进行评估,然后用一组超参数,选择在验证集上表现最好的分类器。当完成了这些步骤之后,我们就完成了所有的测试。再把这组在验证集上表现最佳的分类器拿出来,在测试集上跑,这个才是你需要写到论文中的数据。因此我们必须分类验证数据和测试数据。

另外一个设定超参数的办法是交叉验证。这在小数据集中更常用一些。在深度学习中不那么常用。它的理念是我们取出整个数据,然后将整个数据集中的部分数据保留作为最后使用的测试集,然后剩余部分,不是分成一个训练集合验证集,而是将训练数据分成很多份,在这种情况下,我们轮流将每一份当做验证集,用一组超参数来训练你的算法,现在前4份上训练,在第五份上验证,然后再次训练算法,在1、2、3、5份上训练,在第4份上验证,然后对不同分进行循环,当这么做了你会有更强的信心,哪组超参数的表现更稳定。所以这似乎是一种黄金法则,但是事实上,在深度学习中,当我们训练大型模型时,训练本身非常消耗计算能力,因此这些方法实际上不常用。

一般的做法是将收集到的数据随机打乱,然后随机分成训练集、验证集、测试集。最后你会根据验证集上的表现选择相应的K值和超参数。
但是KNN很少用在图像分类中,首先是它在测试时运算时间比较长,这和我们刚刚提到的需求不符。另外一个问题是像L2或者L1距离的衡量标准,用在比较图像上不合适。这种向量化的距离函数,不太适合表示图像之间视觉的相似度。究竟我们是如何区分图像中的不同的呢?比如原始图片是左边这位女士的图片,需要对比的图片是右边三张经过不同处理的图片,如果计算原图和后面三张图之间的L2距离,其值是一样的。但是这并不是我们想要的,因此L2不适合用来表示图像之间视觉感知的差异。
KNN算法还有另外一个问题,计算维度灾难。根据KNN的描述,它有点像是用训练数据,把样本空间分成几块,这意味着如果我们希望分类器有好的效果,我们需要训练数据能够密集地分布在空间中,否则最近邻点的实际距离可能很远,也就是说和待测样本的相似性没有那么高。而问题在于想要密集地分布在空间中,我们需要指数倍的训练数据,我们不可能拿到那么多的图片去密布到整个空间中。
注意:维度灾难
假设样本点取n维,样本选取的标准是为了覆盖总体20%的范围特征。
我们假设样本点每个维度都有10个可能的取值。
1. 当n为1时
则总体数量为10,只需要2个样本就能覆盖总体的20%
2. 当n取2时
有两个维度,这时总体的数量变为100(10*10),那么就需要20只了。
3. 当取n时
共有10n个数量,样本应取10n∗0.2个。
注意,这与我们平时理解的总体不一样。
因为总体的数量从一开始就是固定的,比如,全世界有1亿只苍蝇,如果只需要拿红眼和白眼来作为区分,那么可能取5只就够了,但如果增加属性的维度,比如在增加翅膀长度,个体大小,年龄,那么需要的果蝇数量将呈指数级增长。这是导致维度灾难的主要原因。
从这个意义上说,不仅是knn,其他分类算法都会遇到维度灾难的问题。
图像分类:线性分类器
线性分类器有利于我们建起整个神经网络,和整个卷积网络。我们经常把神经网络比喻为乐高,你可以拥有不同种类的神经网络组件,你可以将这些组件组合在一起,来构建不同的大型卷积网络 ,线性分类器就是这些简单的组件。
比如我们的输入是一副图片,那么输出为这幅图像的一个描述。卷积神经网络只关注图像,而循环神经网络只关注语言,因此我们需要将两个网络连接在一起,就像玩乐高一样,再将其一起训练。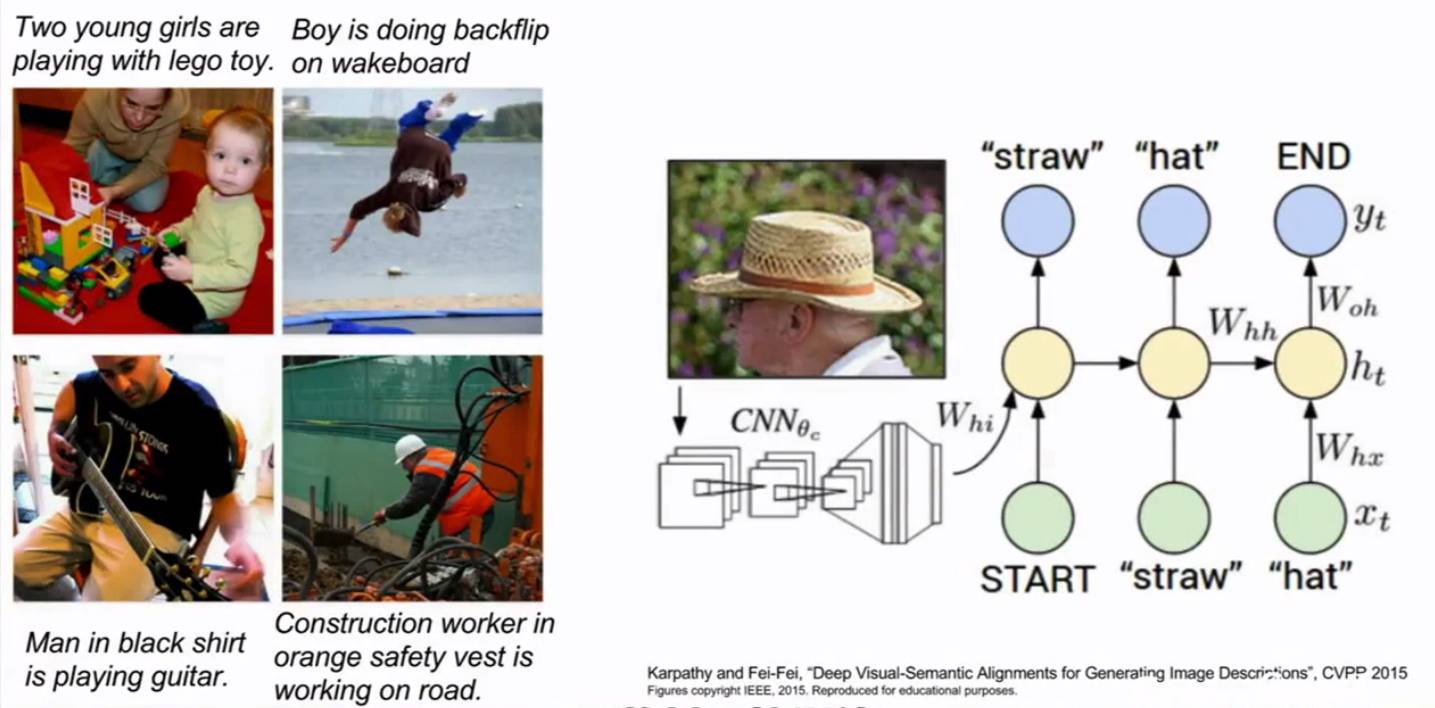
在KNN中我们没有设置参数,我们会保留所有的训练数据,但是在一个参数化的方法中,我们将总结我们对训练数据的认识并把所有的知识都用到这些参数w中,在测试的时候我们不再需要实际的训练数据,我们可以把它扔掉,在测试的时候,只需要这些参数W,这使得我们的模型更有效率。
线性分类器是参数模型中最简单的例子,输入的是图像,写入X,W为一组权重,输出为分类为各个类别的分数,那个得分最高的类别就为此输入的类别。X为一个3072*1的矩阵,W为10*372的矩阵,因此两者相乘为10*1,得到的就是10个类别所对应的分数。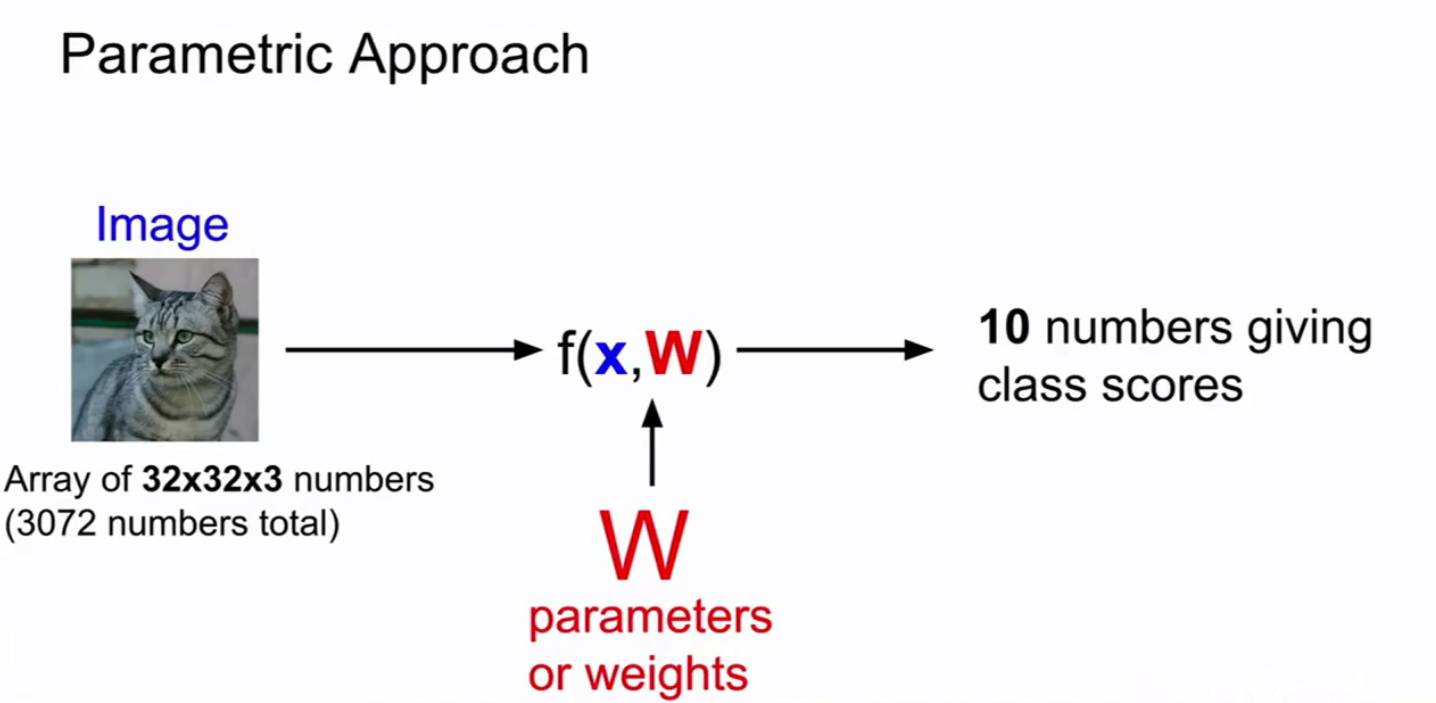
因此每个类别都对应了一组权重W,也就是对应了一个类别,一旦出现了变形,一个单独的模板就不行了。线性分类器企图在决策边界画出一条线来区分不能的类别。
但是有些数据集就不能用一个线性分类器来分类。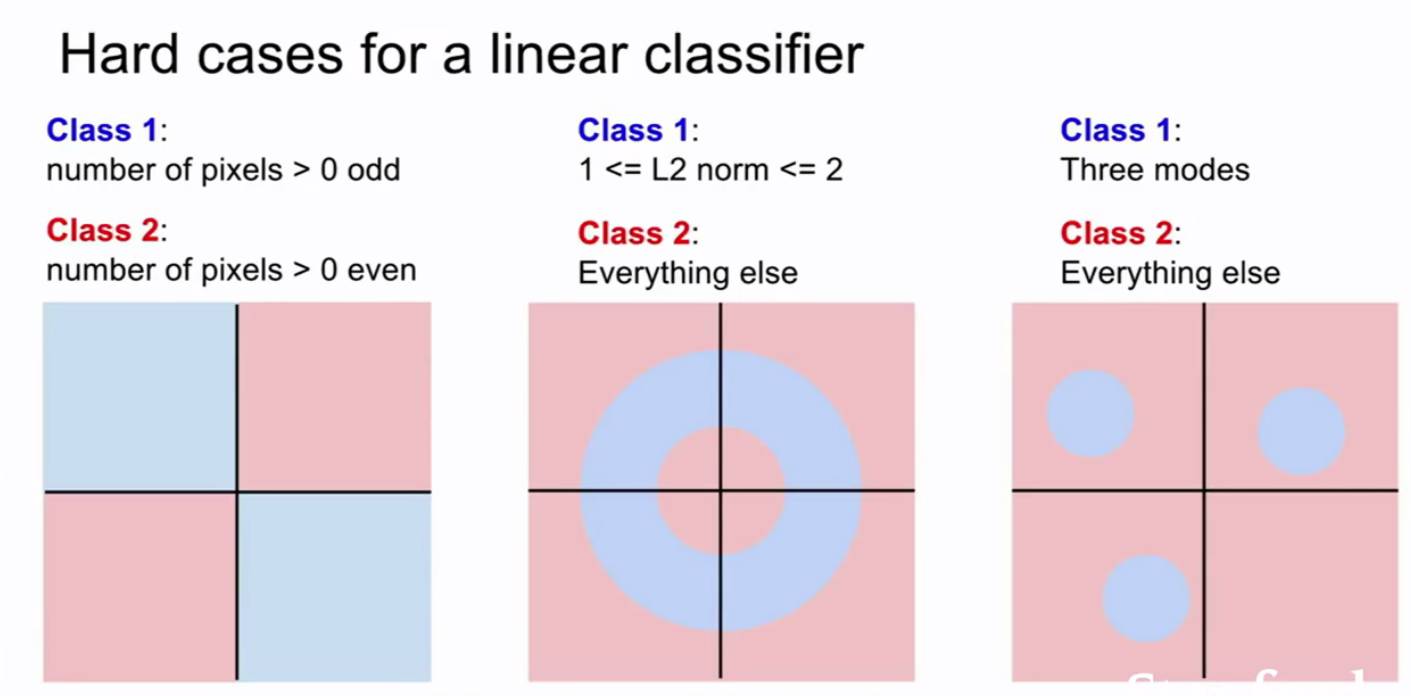
功能函数为:f(x,w)=x*w+b,b为偏差
交叉验证 超参数
线性分类
损失函数
import numpy as np from numpy.random import randn N,D_in,H,D_out=64,1000,100,10 x,y=randn(N,D_in),randn(N,D_out) w1,w2=randn(D_in,H),randn(H,D_out) for t in range(2000): h=1/(1+np.exp(-x.dot(w1))) y_pred=h.dot(w2) loss=np.square(y_pred-y).sum() print(t,loss) grad_y_pred=2.0*(y_pred-y) grad_w2=h.T.dot(grad_y_pred) grad_h=grad_y_pred.dot(w2.T) grad_w1=x.T.dot(grad_h*h*(1-h)) w1-=1e-4*grad_w1 w2-=1e-4*grad_w2 class Neuron: # ... def neuron_tick(inputs): """ assume inputs and weights are 1-D numpy arrays and bias is a number""" cell_body_sum=np.sum(inputs*self.weights)+self.bias firing_rate=1.0/(1.0+math.exp(-cell_body_sum)) return firing_rate # forward-pass of a 3-layer neural network: f=lambda x:1.0/(1.0+np.exp(-x)) x=np.random.randn(3,1) h1=f(np.dot(W1,x)+b1) h2=f(np.dot(W2,h1)+b2) out=np.dot(W3,h2)+b3

 客服1
客服1
 官方群
官方群