

¥
支付方式
请使用微信扫一扫 扫描二维码支付
请使用支付宝扫一扫 扫描二维码支付


在线性分类器中,W是一个分类模板,体现了所有训练数据的经验知识,而W是通过训练过程得到的;线性分类的过程很简单, 当输入一张图片,将此图片拉长成一个三维长向量,乘以参数矩阵W,得到所有分类的评分,某一类的得分最高,就将此输入的图片分为哪一类。如果某一类的得分很低,那么就表示输入为此类的概率很小。当W的值不同的时候,得到的分类分数也不同,要使得分类正确的概率最高就需要选择最佳的W,那么就需要损失函数。损失函数是所有样本的预测分数与实际分数的差的平均值。

在两类SVM中,分类类别为正例和反例。

在这个例子中,输入为猫的损失函数为:Li=max(0,5.1-3.2+1)+max(0,-1.7-3.2+1)
在SVM中,损失函数在所有错误分类的分数小于正确分数分类的分数,或者正确分类的分数超过错误分类的分数一定的边界,则定义损失函数为0;如果错误分类的分数大于正确分类的分数,那么损失函数就是所有样本错误分类的分数的平均值。Sji为正确分类的分数;此函数就像一个合页。随着正确分类的分数增加,其损失函数越低。损失函数的值最小为0,最大为无穷大。在最初训练的时候,我们会初始化W的值。如果所有的分数都差不多,当使用多分类SVM时,那么损失函数将会是分类类别-1;因为所有的错误分类数为c-1,损失函数就存在c-1个为的边界。损失函数如果不使用求和而使用平均值的话其最终的值是没有差别的。如果算上所有的类别, 那么损失函数加上1.
代码例子:

那么有一个问题是当损失函数为0的时候,其W是不是唯一的呢?当然不是唯一的。
但是分类器的目的不是在为了拟合训练数据,而是如何在测试数据上有好的效果,因此我们在损失函数上加了一项正则项,使得模型更加简单,可以在测试数据上有更好的表现。
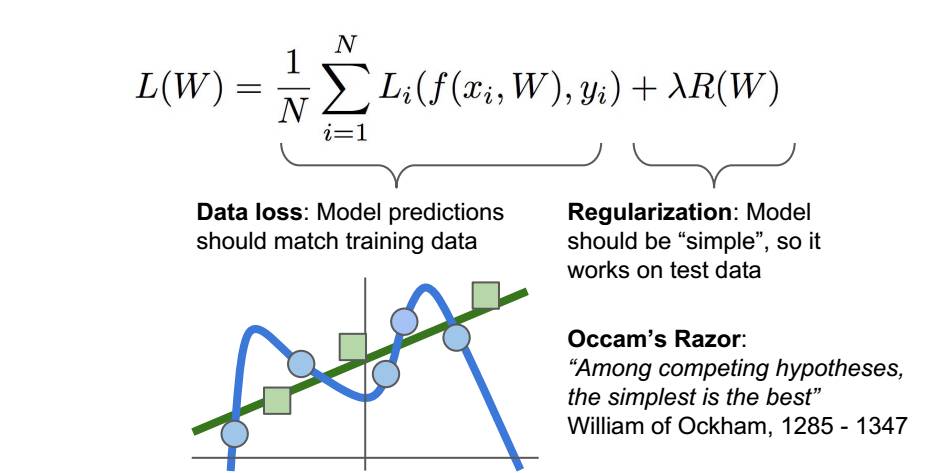
超参数是为了平衡这两项。在实际训练中,对于模型的训练时间影响很大。
加入正则化主要目的是为了防止模型过拟合,过拟合就是模型在训练数据上的表现很好,但是在测试数据上表现很差的现象。模型为了拟合所有的训练数据,w就看一取任意值变得很不稳定。加入了正则项就是给W加了先验知识,使得模型简化,避免过拟合。
正则化一般有两种,L1范数和L2范数。
CS331 and CS431 for advanced topics in computer vision
- L1方形距离坐标,L2圆形距离坐标
- 大部分训练集,验证集,测试集
- 小数据时:交叉验证,确定超参
- 训练集和验证集的区别
- 线性分类
- 卷积神经网络与循环神经网络各司其职,基础模块构成大的模型,类似于乐高玩具一样
- 模板匹配
- f(x,W)=Wx+b
设置最佳的超参数:
(1)将数据分为训练集,验证集,测试集。
通过验证集选择最佳的超参数。
(2)交叉验证(小数据集)分为训练集,测试集。
将训练集数据分为若干组,选取其中一组作为验证组,其他组为训练组。不断更换验证组来进行验证。
注:不适合深度学习,训练非常消耗计算能力。
对于图片来说,运用平移渲染,使得图片产生变化,但是L2的距离并没有改变。从而导致算法并不能区分不同的图片。
KNN算法对于潜在的各种分布情况没有任何预设,唯一能正常工作的方法是在样本空间上有密集的训练样本。
线性分类器:
f(x,w)=Wx
lecture 1
相关课程

 客服1
客服1
 官方群
官方群