




¥
支付方式
微信支付
支付宝支付
¥
请使用微信扫一扫 扫描二维码支付
¥
请使用支付宝扫一扫 扫描二维码支付
1966年: MIT--THE SUMMER VISION PROJECT
70年代: MIT--David Marr: A BOOK that 2D raw image to 3D model:
原始图像:边缘顶点和虚拟线条曲线边界,早期对图像的处理主要集中在边缘的简单处理
2.5维草图:将表面,深度信息,层或者视觉场景的不连续性拼凑在一起
将表面和体积图放在3d模型里
这种思维影响了计算机视觉领域很久,是传统的方式
70年代 另一个有影响的:如何越过简单的块状直接识别和表示图像
将物体的复杂结构简约城一个更简单的形状和结构,重新表达。
80年代:识别并重建,大部分都是直线和直线之间的关系。
总结:60-80年代,识别计算机视觉中的物体都是只停留在少样本的简单的几何图像,没有太多进展。
------------------------------
图像目标分割:将图像中的像素点进行归类
面部监测:1999-2000 机器学习加速发展,svm,boosting ,图模型等
2006年,实时监测面部的数码相机
基于特征的目标识别,sift特证
空间金字塔匹配:将各种物体的最为一个特征,放在SVM中计算
方向梯度直方图,可变形部件模型,识别人体姿势。
总结:随着各方向发展,21世纪早期,非常重要的基本问题--目标识别。
有名的标注数据集:基于2007-2012年PASCAL性能提升
同期提出了:是否具备了识别世界中所有物体的能力,或者大部分物体。
大部分的机器学习算法,都很可能在训练的过程中过拟合,太复杂导致模型维数太高,无法很好的泛化,当训练数据量不够时,就产生了过拟合问题,ImageNet项目来解决这个问题。
ImageNet带来巨大的数据集,将目标检测算法发展到新的高度。
2010年:ImageNet举办了挑战比赛,分类识别检测计算机视觉算法。
2010-2015年错误率一直下降,低于人类。2012年错误率显著下降,而其算法就是卷积神经网络的深度学习算法。
1.每一个对象都由简单的几何图单位组成。
2.剃须刀通过边缘和直线进行识别
3.对象识别太难了,我们先要做的就是先要分割对象---图像分割
4.进一步发展--人脸识别
5.找到某些特征,,他们往往能够在变化中具有表现性和不变性,,所以首要任务就是把这些进行对比,简化操作(不用对比整个图像)
6.卷积神经网路 模型 实践
7.
计算机视觉的发展历史:
动物进化出眼睛;生物视觉-》机器视觉-》照相机;
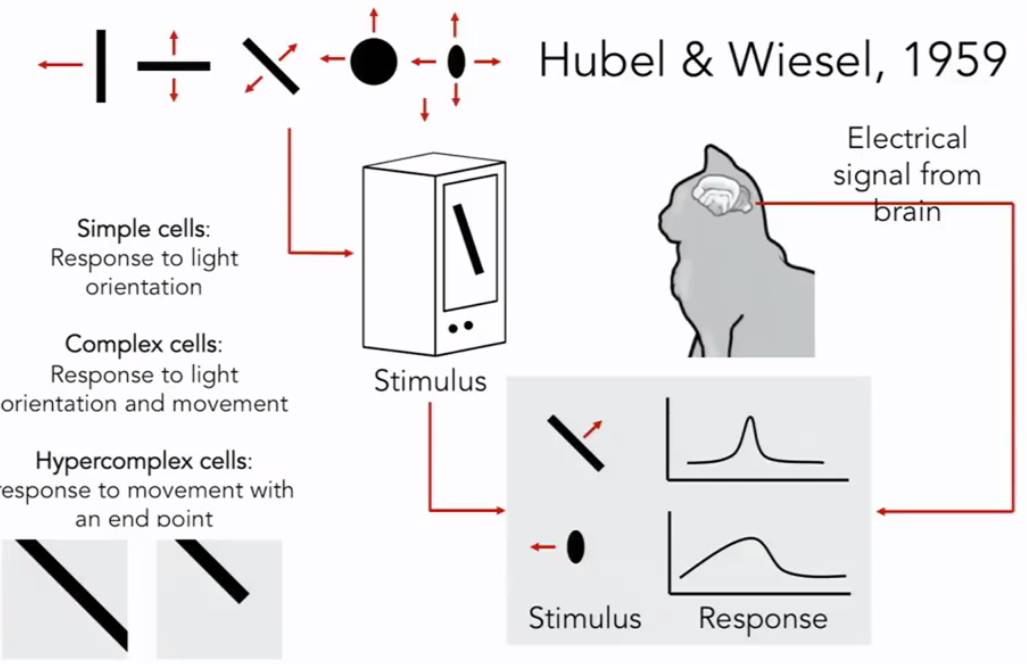
生物学家开始研究视觉的机理,Hubel & Wiesel,1959,他们的问题是:哺乳动物的视觉处理机制是怎样的呢?他们讲电极插进主要控制猫视觉的后脑上的初级视觉皮层,然后观察,何种刺激会引起视觉皮层神经元的反应。他们发现猫的大脑的初级视觉皮层有各种各样的细胞,其中最重要的细胞是当它们朝着某个特定的方向运动的时候,对面向边缘产生回应的细胞。当然还有更加复杂的细胞,但是总的来说,它们发现视觉初级是始于视觉世界的简单结构,面向边缘,沿着视觉处理途径的移动,信息也在变化,大脑建立了复杂的视觉信息,直到它可以识别更为复杂的视觉世界。
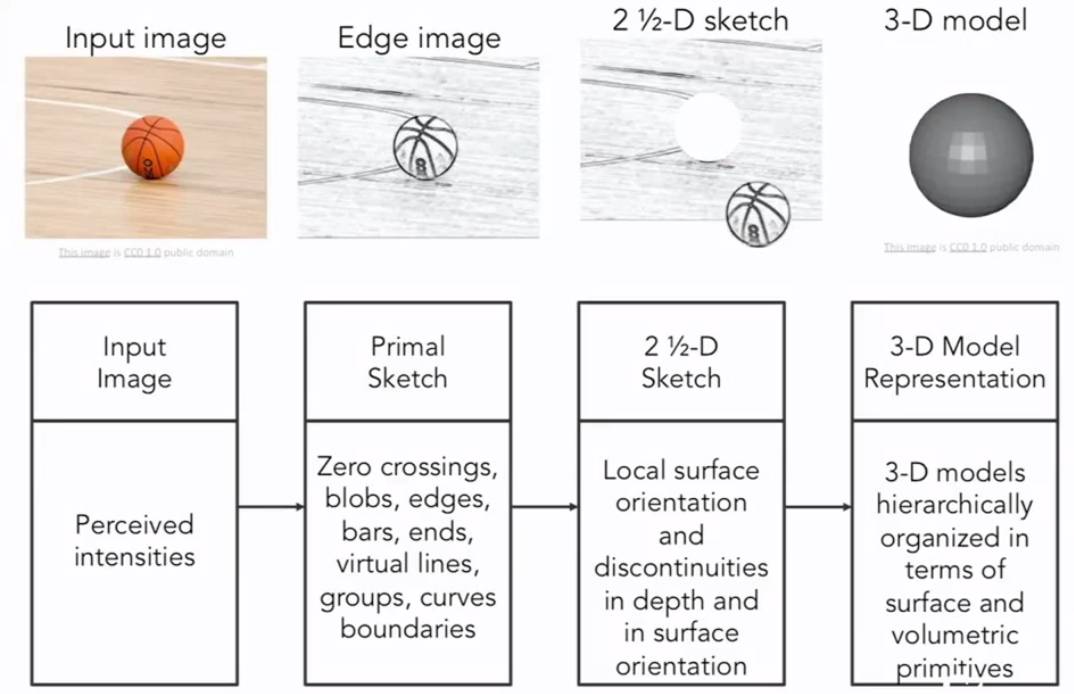
计算机视觉的历史是从60年代初开始的,Block World 是由Larry Roberts出版的一部作品,被广泛地称为计算机视觉的第一篇博士论文,其中视觉世界被简化为简单的额几何形状,目的是能够识别它们,重建这些形状是什么。1966年MIT的暑期视觉项目,目的是为了构建视觉系统的重要组成部分。David Marr,一个MIT 视觉科学家提出了使得计算机识别视觉世界的算法,他指出,为了获取视觉世界完整的3D图像,需要经历几个阶段:第一个阶段是原始草图,大部分边缘、端点和虚拟线条,这是受到了神经科学家的启发,Hubel &Wiesel 告诉我们视觉处理的早期阶段有很多关于像边缘的简单结构;第二阶段是David Marr 所说的“2.5维草图”我们开始将表面、深度信息、不同的层次以及视觉场景的不连续性拼凑在一起的;最后一个阶段是将所有的内容放在一起,组成一个3D模型。这是一个非常理想化的思想过程,这种思维方式实际上已经在计算机视觉领域影响了几十年。这也是一个非常直观的方式,并考虑如何解构视觉信息。
七十年代另外一个非常重要的工作(Brooks&Binford,1979 Fischler & Elschlager 1973),这个时候他们提出了一个问题,我们如何越过简单的块状世界,开始识别和表示现实世界的对象。70年代是一个没有数据可用的时代,计算机的速度很慢,计算机科学家开始思考如何识别和表示对象,在斯坦福大学的帕洛阿尔托以及斯里兰卡提出了类似的想法,一个被称为广义圆柱体,一个被称为圆形结构,他们的基本思想是每个对象都是由简单的几何图单位组成,任何一种表示的方法就是讲物体的复杂结构,简约成一个集合体,有更简单的形状和几何结构,这些研究已经影响了很长很长的一段时间。
80年代,David Lowe思考如何重建或者识别由简单的物体结构组成的视觉空间,他尝试识别剃须刀,通过先和边缘进行构建,其中大部分都是直线以及直线之间的组合。那个时候由于样本小,物体识别是很难的。
如果物体识别太难了,那么我们首先要做的是目标分割,这个任务就是把一张图片中的像素点归类到有意义的区域,我们可能不知道这些像素点组合到一起是一个人型,但是我们可以把这些属于这人的像素点从背景中抠出来,这个过程就叫做图像分割,这项工作是由Berkeley的 Jitendra Malik和他的学生Jianbo Shi 所完成的。他们用一个图论算法对图像进行分割,还有另外一个问题,先于其他计算机视觉问题有进展,也就是面部检测,脸部是人类最重要的部位之一。
1999-2000年机器学习技术,特别是统计机器学习方法,开始加速发展,出现了很多方法:支持向量机模型,boosting方法,图模型。有一种工作做出了很多贡献,技术使用AdaBoost 算法进行实时面部检测,由Paul Viola和Michal Jones 完成。在他们发表论文后的第五年,也就是2006年,富士康推出了第一个具有实时面部识别的照相机。这是从基础科学研究到实际应用的一个快速转化,关于如何才能能够做到更好的目标识别,这是一个我们可以继续研究的领域。从90年代末到2000年的前十年有一个非常有影响力的思想方法是基于特征的目标识别,这里有一个影响深远的工作,由 David Lowe完成,叫做SIFT特征,思路就是去匹配整个目标。例如这里有一个stop标识去匹配另外一个stop标识是非常困难的,因为有很多变化的因素,比如相机的角度、遮挡、视角、光线以及目标自身的内在变化,但是可以得到一些启发,通过观察目标的某些部分,某些特征是能够在变化中保持不变性,所以目标识别的首要任务是在目标上确认这些关键的特征,然后把这些特征与相似的特征进行匹配,它比匹配整个目标要容易得多。我们这个领域另外一些进展是识别整幅图的场景,有一个算法叫空间金字塔匹配,背后的思想是图片里面有各种特征,这些特征可以告诉我们这是哪种场景,到底是风景还是厨房,或者是高速公路等等 。这个算法从图片的各部分,各个像素抽取特征,并把他们放在一起,作为一个特征描述符,然后在特征描述符上做一个支持向量机。有个在人类认知方面很类似的工作正处于风头浪尖。有些工作是把这些特征放在一起之后,研究如果在实际图片中合理地设计人体姿态和辨认人体姿态,这方面一个工作被称为方向梯度直方图;另外一个被称为可变形部件模型。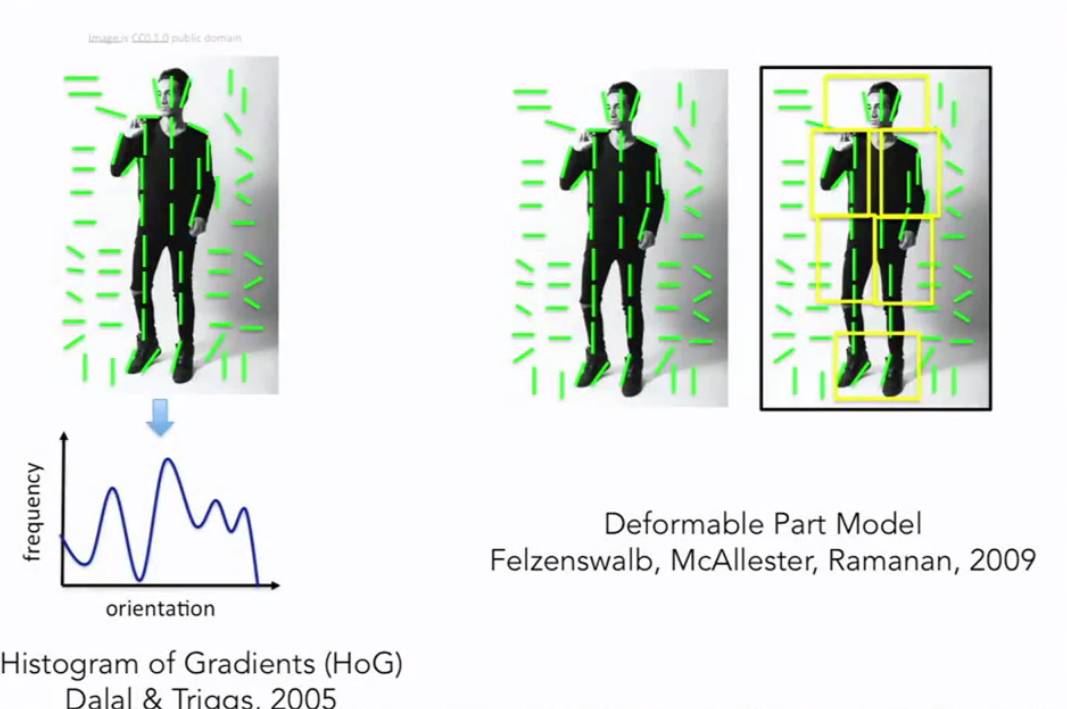
可以看到我们从60年代、70年代、80年代一步步走到20世纪,有一件事情一直在变化,就是图片的质量,随着互联网的发展,随着数码相机的发展,计算机视觉的研究也能拥有更好的数据了,计算机视觉在21世纪早期提出了一个非常重要的基本问题,我们一直在目标识别,但是直到21世纪的早期,我们才开始真正拥有标注的数据集,能供我们衡量在弥补识别方面取得的成果,其中最具有影响力的标记数据集之一叫PASCAL Visual Object Challenge 这个数据集由20个类别的图片,数据集中的每个种类都有成千上万张图片,
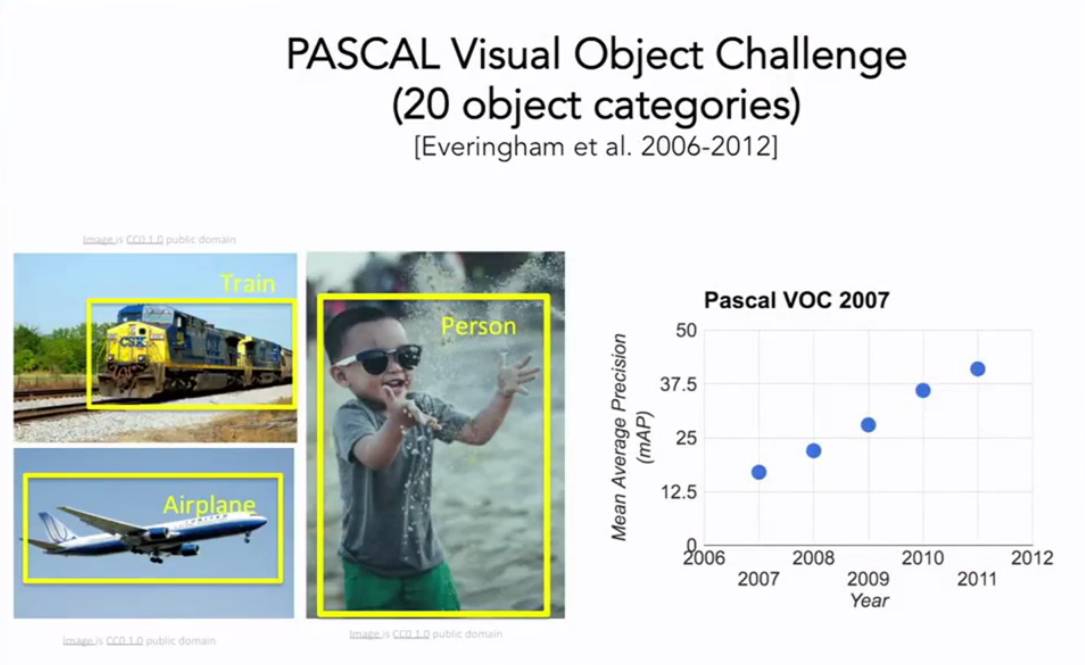
现场不同的团队开发算法来和数据测试集做对抗训练,来看有毛毛雨优化,这里有一张图表列举了从2007年到2012年在基准数据集上检测图像中的20中目标的检测效果,可以看到在稳步提升。在差不多时候,普林斯顿和斯坦福中的一批人开始,向我们或者说我们这个领域提出了一个更加困难的问题,我们是否具备了识别真实世界中的每一个舞台的能力,或者说大部分物体。这个问题是由机器学习中的一个现象驱动的,就是大部分的机器学习算法,无论是图模型,还是支持向量机或者是AdaBoost都可能会在训练过程中过拟合,部分原因是可视化的数据非常复杂,我们的模型的维数就很高,参数量就很大,输入是高维的模型,则还有一堆参数需要调优,当我们的训练数据量不够时,很快就产生了过拟合的现象,这样我们就无法很好地泛化,因此即使有两方面的动力,一是我们单纯地想识别自然世界中的万物,二是要回归机器学习克服机器学习中的瓶颈问题,过拟合问题。 LIfeifei开展了一个叫ImageNet的项目,汇集所有能够找到的图片,包含世界万物,组建一个尽可能大的数据集,用一个称为WorldNet的字典来排序,这个字典里有上万个物体类别,用亚马逊土耳其机器人平台进行排序清洗数据,给每张图片打上标签,最终的结果是一个ImageNet,最后由将近500万甚至4000万多的图片,分成22000类的舞台或者场景,这是一个巨大的,很有可能是由当时AI领域最大的数据集,它将目标检测算法的发展推到了一个新的高度。从2009年开始,ImageNet团队组织了一场国际比赛,叫做ImageNet大规模视觉识别竞赛,这是一个筛选更严格的测试集,总共140万的目标图像有1000种目标类别,分别识别来测试计算机视觉算法。2012年卷积神经网络算法击败了所有其他的算法。CNN模型展现了强大的能量。
The critical steps of the development of object recognition:
1.image segmentation
Reducing the complex structure of the object to simple structure
2.face detection
ML:SVM、boosting
Adaboost——face detection
3.feature matching
SIFT feature-The idea is that to match
some features tend to remain diagnostic and invariant to changes(某些特征能够在变化中具有表现性和不变性)
the task of object recognition is identifying these critical features(关键的特征) on the object and then match the features to a similar object
4.recognize holistic scenes——spatial pyramid matching(algorithm)
There are features in the images that can give us clues about which type of scene it is.
5.object recognition
The comman data set of deep learning:
1.MNIST
2.PASCAL Visual Object Challenge
3.ImageNet
4.COCO
1. 到2016年为止,我们的世界85%都是以像素形式呈现的。而像素数据就好像暗物质,虽然无法具体的描述出来,但是可以用数学模型来进行推断和模拟。在Youtube上面,平均每60秒就有150小时的视频上传,这意味着大量像素数据需要被标记、分类以及索引等等操作以便广告商或者用户检索等功能的相关应用扩展。
2.随着互联网逐渐成为人类获取信息的主要载体以及视觉传感器(如智能手机、行车记录仪等设备)数量的增多,计算机视觉逐渐走入人们的视线,计算机视觉和很多领域都密切相连,跨学科。属于深度学习的一个超集(即深度学习也属于计算机视觉的一个子集,即在计算机视觉领域的一个发展子方向)
【深度学习和机器学习的差别?深度学习是机器学习的更高级的算法 (深度学习不是算法,是一种层次化分解任务的思想—>传统机器学习一步一步进行,具有算法的步骤;而深度学习则是多层次处理,对数据进行每一步特征提取具有整体性(所有层都是一个整体,就像编译型,传统就像解释型),原始信息不易丢失(传话),避免多层的噪声引入),比之机器学习具备多层架构的感知器,正确率更高,如果这样看,可以说机器学习是深度学习的超集】—>【与本课程相联系的—在ImageNet 竞赛中,2012年后,基本所有夺冠模型都使用了使用了卷积神经网络,取代了以前特征提取+向量机的方法】
3.计算机视觉的历史:
(1).五亿四千万年前,寒武纪生命大爆发,Andrew Parker:这一切都源于眼睛的出现。
(2).文艺复兴时期:达芬奇发明的camero obscura,照相暗盒。现代视觉工程技术的开端。“复制这个世界”,但此时人们对视觉的需求不涉及理解。
(3).哈佛的研究:清醒但是被麻醉的猫,用一根电极探针插入猫的基础视觉皮质层—整个视觉处理流程的前期开端(在后脑勺部位。50%的大脑参与了视觉处理),记录神经元的活动。每次换幻灯片的动作会使得神经元被激活,生成了一个边缘刺激神经元的激活,每一列神经元按序排列,对特定的有反应。此时人们开始尝试理解视觉,并意识到视觉处理的前期是对简单的结构形状和边缘结构(由一些允许变形的“弹簧”连接。)进行处理和解析。(方块世界)
(4).David Marr:视觉是分层的。第一层是边缘结构(原始草图);第二层是2.5D—将2D视觉成像处理为3D真实世界模型(即遮挡问题等)。此时人们研究的方向转为研究如何重建一个3D模型,以便我们识别。
(5).在1997年,VIOLA JONES FACE DETECTOR实现人脸检测(富士2006数码相机),虽然这个模型没有用到深度学习,但是运用了特征学习的思想,算法试图寻找黑白的过滤器特征值(向量在此变换下缩放的比例)。人们开始处理彩色图像,将图片分割成有意义的几部分,将像素进行分组。此时人们研究的重点从建立3D建模跳到了我们识别的是什么。
(6).Kunihiko Fukushima: (邦彦福岛)提出了Neocognitron模型—现代神经网络架构的开端。
Yann Lecun 反向传播和学习策略 识别手写数字:边缘结构—滤波—池化等
【Neocognitron模型的优化:竞赛中也有人使用了Neocognitron模型,但是在顺序和量级两个方面进行了优化。不同的在于运用了 1.摩尔定律。解决算法太慢等问题 2.大数据。高性能架构的执行力,解决过拟合overfitting(为了得到一致假设而使假设变得过度严格,没有从带干扰的观察中找到事物真正的规律。除了学习的全局特征,如果样本存在太多局部特征则会使得预测不准确。于是机器无法正确识别符合概念定义的“正确”样本的几率也会上升,也就是所谓的“泛化性”变差,这是过拟合会造成的最大问题.)的问题。】
4.仍在研究中的技术:密集检测、动作场景方面、3D方面
5.愿景:
1.Neural Style
Github:https://github.com/jcjohnson/neural-style
这个项目是对论文“A Neural Algorithm of Artistic Style”用深度学习框架Torch7 的一个实现。该论文提出一种采用卷积神经网络将一幅图像的内容与另一幅图像的风格进行组合的改进算法。例如将梵高《星夜》的艺术风格转移到斯坦福大学校园夜景的照片中.
2.Show and Tell
GitHub:https://github.com/tensorflow/models/tree/master/im2txt
这是 论文Show and Tell: Lessons learned from the 2015 MSCOCO Image Captioning Challenge 用TensorFlow实现的 image-to-text 图片说明生成模型.即给机器一张图片,生成解释的文字。
3.Neural Doodle
Github:https://github.com/alexjc/neural-doodle
基于Combining Markov Random Fields and Convolutional Neural Networks for Image Synthesis中的 Neural Patches 算法,根据文章Semantic Style Transfer and Turning Two-Bit Doodles into Fine Artworks,使用深度神经网络把你的二流涂鸦变成艺术一般的作品的一个实现。
4.Open Face
Github: https://github.com/cmusatyalab/openface
OpenFace 是一个使用深度神经网络,用 Python 和 Torch 实现人脸识别的项目。神经网络模型基于 论文FaceNet: A Unified Embedding for Face Recognition and Clustering,Torch7 让网络可以在 CPU 或 CUDA 上运行。
5.PaintsChainer
http://paintschainer.preferred.tech/
Github: https://github.com/pfnet/PaintsChainer
PaintsChainer可以给手绘的线稿进行自动上色,并且可以规划不同区域的不同颜色进行定制上色。
History of computer vision
AdaBoost:人脸识别
目标识别:SIFT特征:思路:匹配整个目标
目标识别的首要任务是在目标上确认这些关键的特征,然后把这些特征与相似的目标进行匹配,它比匹配整个目标要容易很多。
相关课程

未来汽车大讲堂——智能驾驶第一课
¥399.00
¥599
会员¥258
开课日期:直播已结束,可回看开始
从Python入门-如何成为一名AI工程师
¥299.00
¥499
会员免费
开课日期:开始
授课教师
暂无教师
微信扫码分享课程
 客服1
客服1
 官方群
官方群