



改变坐标轴会改变L1
但是 不会L2
L1:在各个坐标有个实际意义时候表现更好
k是超参数 是学不到的
不能总是调整 超参数 使得训练结果最好
也不能使得验证结果最好
也就是你不不能瞎几把调
还有一种方法:交叉验证(小数据集中使用)
把训练集分成4组,交叉验证
knn分类局限性:1、就是用数据将把样本空间分成几块
如果维度太高,那数据太少肯定不行,数据必
须密集
2、L1 L2距离并不能真实地反应两张图的差别
¥
支付方式
请使用微信扫一扫 扫描二维码支付
请使用支付宝扫一扫 扫描二维码支付
改变坐标轴会改变L1
但是 不会L2
L1:在各个坐标有个实际意义时候表现更好
k是超参数 是学不到的
不能总是调整 超参数 使得训练结果最好
也不能使得验证结果最好
也就是你不不能瞎几把调
还有一种方法:交叉验证(小数据集中使用)
把训练集分成4组,交叉验证
knn分类局限性:1、就是用数据将把样本空间分成几块
如果维度太高,那数据太少肯定不行,数据必
须密集
2、L1 L2距离并不能真实地反应两张图的差别
K-Nearest Neighbor在图像处理的几个问题
1 欧式距离不能处理Boxed Shifttd Tinted
2 Curse of dimensionality维度灾难
KNN
L1distance(Manhattan):depends on the choice of coordinates system, when changing the coordinate frame, that would actually change the L1 distance between the points.
L2distance(Euclidean): it's the same thing whatever the coordinate frame is.
For the input features, if the individual entries in the vector have some important meaning for the task, then L1 may fit.
But if it's just a generic vector in some place, then the L2 maybe more natural.
In KNN, there are two major choices that we should select:
the K value
the distance metric
hyperparameters:the choices about the algorithm that we set rather than learn:
How do you actually make these choices for your problem and for your data?
setting hyperparameters:
常用:分为训练集,验证集和测试集;在训练集上进行训练,然后把在验证集上表现最好的模型用于测试集。
交叉验证:小数据,深度学习不常用。数据分为多份,最后一份作为测试集,剩下的其中一份轮流当验证集,剩余的为训练集。
distance metics and values of K
knn K nearest Neighbors k个最最临近的值
两种位置的计算方法:
曼哈顿距离与欧顿距离
超参数
选择超参数的方法:
给出训练集
验证集与测试集
在最后去使用测试集去验证
验证集与训练集可以轮流交叉选取。
KNN训练简单,只需要记录信息即可。
但测试时时间太长
不太好:
1.计算距离的方式,不太适合图像的表达
2.维度越高,需要的训练数据越多,但我们并没有这么多训练数据
Manhattan distance
Euclidean distance
交叉验证在小数据集上应用更多,深度学习中不常见
维度灾难
K最近邻算法
Nearest Neighbour是K-nearest Neighbour 中K=1情况。分类效果往往不好,所以一般会给K赋一个稍大的值以取得更好的分类效果。
(1)K-Nearest Neighbours选择Distance Metirc(距离度量)
1. L1(Manhattan)distance
像素之间绝对值的总和
2. L2(Euclidean)distance
取平方和的平方根。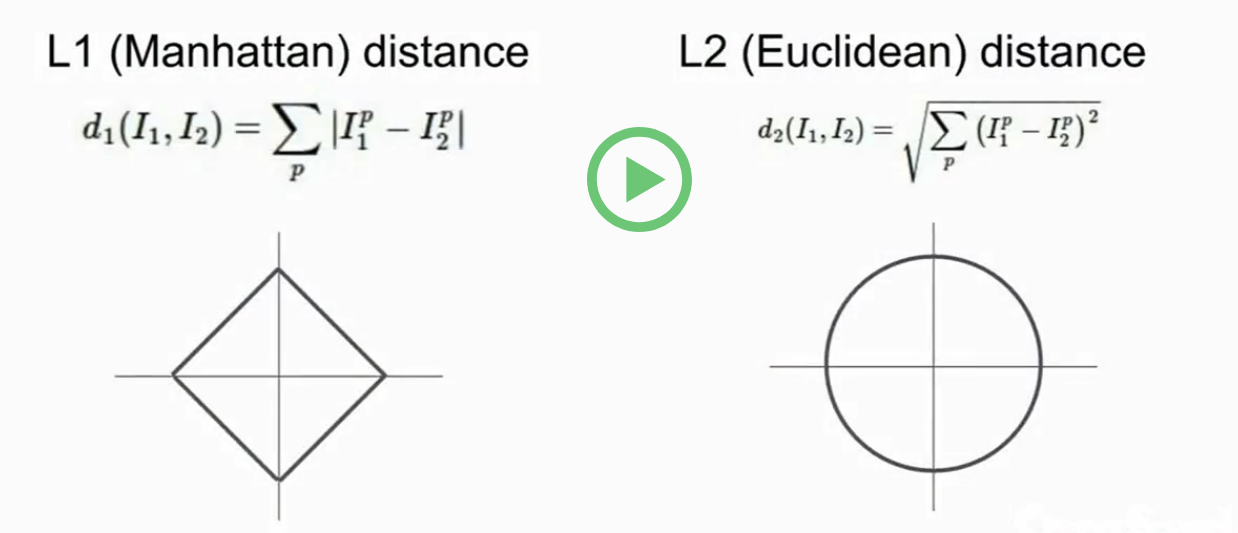
hyperparameters(超参数):是自己设置而不是学习到的。不同的问题有不同的超参数。
例子:上述的K值和距离度量方法都是超参数。
在实际应用中,knn是不会被采用的:
(1)因为测试的时间非常慢(我们期望测试快)
(2)像素的距离度量不是那么有用的信息(L2距离不能很好的衡量图像的相似性)
(3)会产生维数灾难
1.L1距离:它依赖于数据的坐标系统
L2距离:欧氏距离,即:取平方和的平方根
2.L2距离是一个确定的,无论你在什么样的坐标轴下,如果你输入的特征向量,如果向量中的一些值,有一些重要的意义对你的任务,那么也许L1可能更适合,但假如他只是某个空间中的一个通用向量,而你不知道其中的不同的元素,你不知道它们实际上代表的含义,那么L2可能更自然一些
3.简单地通过指定不同的距离度量,我们可以很好地应用这个算法,换句话说就是把不同的距离函数应用到K最近邻算法上,可以取得不同的效果
4.使用这个算法,有几个选择是你需要做的。我们讨论过选择K的不同值,也讨论过选择不同的距离度量,所以问题在于,你该如何根据你的问题和数据来选择这些超参数,所以,像K和距离度量这样的选择,我们称之为超参数,因为他们不一定都能从训练数据中学到,你要提前为算法做出选择,那么问题就在于在实践中,该如何设置这些超参数,这些参数被证明是依赖于具体问题的,多数人会为你的问题和数据尝试不同的超参数的值,并找出哪一个值是最好的
6.尝试不同超参看看哪种更合适,究竟该怎么做呢? 首先想到的是,选择能对你的训练集给出最高准确率,表现最佳的超参数(这也是不明智的)我们关心的不是要尽可能拟合训练集,而是要让我们的分类器,我们的方法在训练集以外的未知数据上表现更好。。最常见的做法就是将数据分为三组,大部分数据作为训练集,然后建立一个验证集,一个测试集。我们常做的是在训练集上用不同的超参来训练算法,在验证集上进行评估,然后用一组超参选择在验证集上表现最好的,然后再把这组在验证集上表现最佳的分类器拿出来在测试集上跑一跑,这才是你写论文中需要的数据
7.训练集与验证集的区别是什么? 训练集就是一堆贴上标签的图片,我们记下标签,要给图像分类,我们会将图片与训练集的每个元素进行比较,然后将与训练点最接近点的标签作为结果,我们的算法会记住训练集中的所有样本,然后我们会把验证集中的每个元素与训练集的每个元素比较,将它作为依据,判定分类器的准确率在验证集上表现如何。你的算法可以看到训练集上的各个标签,但在验证集中,你的算法不能直接看到它们的标签,我们只是用验证集的标签来检查我们算法的表现
8.小结:图像分类的思路:我们借助训练集的图片和相应的标记,我们可以预测测试集中数据的分类
如何比较相邻距离
曼哈顿距离(矩形) 欧氏距离(圆)
文本分类 定义一个距离函数
简单通过指定不同的距离度量
选择:不同K的值 距离度量函数 如何根据自身的额问题来选择这些超参数(这些参数应该初始化,后面会依赖数据)
L1为何要比L2距离表现得好,L1有坐标依赖。
将数据分为三组 训练集 验证集 测试集(去报数据集收到严格的控制)
交叉验证

 客服1
客服1
 官方群
官方群