1.线性分类可以解释为每个种类的学习模板,矩阵W里的每一行都对应着一个分类模板,如果我们能解开这些行的值,那么每一行又分别对应一些权重,每个图像像素值和对应那个类别的一些权重,将这行分解回图像的大小
2.可以用一个函数把W当做输入,然后看一下得分,定量的估计W的好坏,这个函数被称为损失函数(其实就是选择好的权重W)
3.所谓的损失函数,比方来说,有一些训练数据集x,y,通常我们说有N个样本,其中x是算法的输入,在图片分类问题里,x其实是图片每个像素点所构成的数据集,y是你希望算法预测出来的东西,我们通常称之为标签或目标,标签y是一个在1到10之间的整数,这个整数表明对每个图片x哪个类是正确的,我们把损失函数记做L_i
4.我们有了这个关于X的预测函数后,这个函数就是通过样本x和权重矩阵W给出y的预测,在图像分类问题里,就是给出10个数字中的一个,我们可以给出一个损失函数L_i的定义,通过函数f,给出预测的分数和真实的目标或者说标签y,可以定量的描述训练样本预测的好不好,最终L是N个样本损失函数的总和的平均值
5.除了真实的分类Y_i以外,对所有的分类Y都做加和,也就是说我们在所有错误的分类上做和,比较正确分类的分数和错误分类的分数,如果正确分类的分数比错误分类的分数高,比错误分类的分数高出某个安全的边距,那么损失为0,接下来把图片对每个错误分类的损失加起来,就可以得到数据集中这个样本的最终损失,S是通过分类器预测出来的类的分数
6.S_Yi表示训练集第i个样本的真实分类的分数
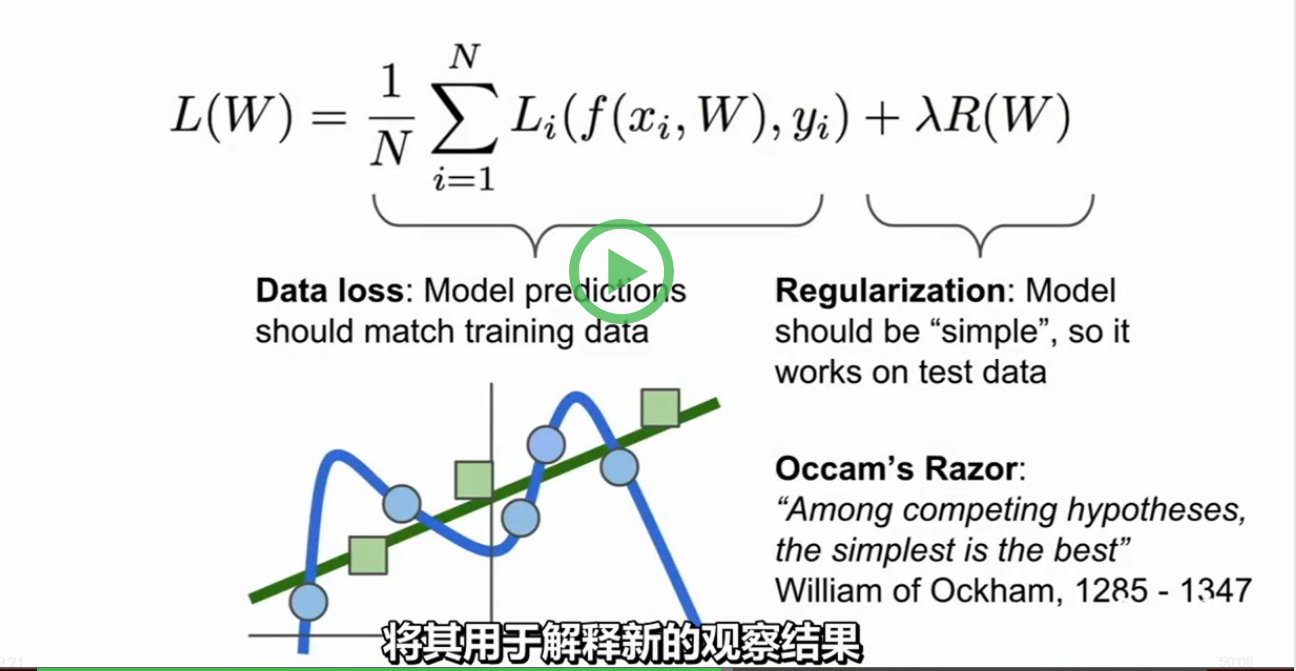
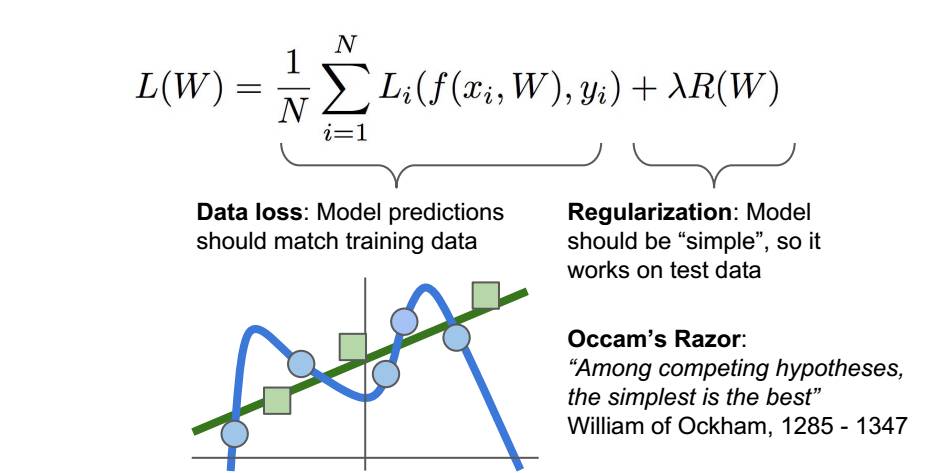
7.分类器如何在这些都是0值的损失函数间做出选择呢? 机器学习的重点是:我们使用训练数据来找到一些分类器,然后我们将这个东西应用于测试数据,所以我们并不关心训练集的表现,我们关心的是这个分类器的测试数据 向损失函数里加入正则化,鼓励模型以某种方式选择更简单的W,这里所谓的简约取决于任务的规模和模型的种类 这样损失函数就有了两个项,数据丢失项和正则项,这里有一些超参数γ用来平衡这两个项
8.正则化 实际上有很多不同的类型正在实践中使用的正则化,最常见的可能就是L2正则化或权值衰减,L2正则化的理念实际上是对这个权重向量的欧式范数进行惩罚。正则化的宏观理念就是:你对你的模型做的任何事,也就是种种所谓的处罚,主要目的是为了减轻模型的复杂度,而不是去试图拟合数据 L1度量复杂度的方式有可能是非0元素的个数,而L2更多考虑的是W的整体分布,所有元素具有较小的复杂性,贝叶斯分类器就可以用L2正则化得到非常好的解释 我的理解:加入正则化就是为了让曲线更加贴近直线,为了使我们的权重系数W变化从而取得最好的分类结果https://www.zhihu.com/question/52398145 有详细解释损失函数。
9.softmax loss softmax直白来说就是将原来输出是3,1,-3的分数通过softmax函数一作用(先指数化,在归一化),就映射成为(0,1)的值,而这些值的累和为1(满足概率的性质),那么我们就可以将它理解成概率,在最后选取输出结点的时候,我们就可以选取概率最大(也就是值对应最大的)结点,作为我们的预测目标!我们用softmax loss对分数进行转化处理并得到正确的类别的损失函数是-log P




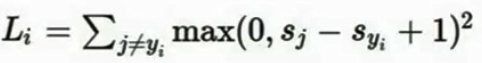 ,会如何?
,会如何?




 客服1
客服1
 官方群
官方群