



【损失函数和优化】
怎么得到线性函数里的W
【多分类SVM】
¥
支付方式
请使用微信扫一扫 扫描二维码支付
请使用支付宝扫一扫 扫描二维码支付
【损失函数和优化】
怎么得到线性函数里的W
【多分类SVM】
损失函数
L = 1/N * L(f, yi)
1.线性分类可以解释为每个种类的学习模板,矩阵W里的每一行都对应着一个分类模板,如果我们能解开这些行的值,那么每一行又分别对应一些权重,每个图像像素值和对应那个类别的一些权重,将这行分解回图像的大小
2.可以用一个函数把W当做输入,然后看一下得分,定量的估计W的好坏,这个函数被称为损失函数(其实就是选择好的权重W)
3.所谓的损失函数,比方来说,有一些训练数据集x,y,通常我们说有N个样本,其中x是算法的输入,在图片分类问题里,x其实是图片每个像素点所构成的数据集,y是你希望算法预测出来的东西,我们通常称之为标签或目标,标签y是一个在1到10之间的整数,这个整数表明对每个图片x哪个类是正确的,我们把损失函数记做L_i
4.我们有了这个关于X的预测函数后,这个函数就是通过样本x和权重矩阵W给出y的预测,在图像分类问题里,就是给出10个数字中的一个,我们可以给出一个损失函数L_i的定义,通过函数f,给出预测的分数和真实的目标或者说标签y,可以定量的描述训练样本预测的好不好,最终L是N个样本损失函数的总和的平均值
5.除了真实的分类Y_i以外,对所有的分类Y都做加和,也就是说我们在所有错误的分类上做和,比较正确分类的分数和错误分类的分数,如果正确分类的分数比错误分类的分数高,比错误分类的分数高出某个安全的边距,那么损失为0,接下来把图片对每个错误分类的损失加起来,就可以得到数据集中这个样本的最终损失,S是通过分类器预测出来的类的分数
6.S_Yi表示训练集第i个样本的真实分类的分数
7.分类器如何在这些都是0值的损失函数间做出选择呢? 机器学习的重点是:我们使用训练数据来找到一些分类器,然后我们将这个东西应用于测试数据,所以我们并不关心训练集的表现,我们关心的是这个分类器的测试数据 向损失函数里加入正则化,鼓励模型以某种方式选择更简单的W,这里所谓的简约取决于任务的规模和模型的种类 这样损失函数就有了两个项,数据丢失项和正则项,这里有一些超参数γ用来平衡这两个项
8.正则化 实际上有很多不同的类型正在实践中使用的正则化,最常见的可能就是L2正则化或权值衰减,L2正则化的理念实际上是对这个权重向量的欧式范数进行惩罚。正则化的宏观理念就是:你对你的模型做的任何事,也就是种种所谓的处罚,主要目的是为了减轻模型的复杂度,而不是去试图拟合数据 L1度量复杂度的方式有可能是非0元素的个数,而L2更多考虑的是W的整体分布,所有元素具有较小的复杂性,贝叶斯分类器就可以用L2正则化得到非常好的解释 我的理解:加入正则化就是为了让曲线更加贴近直线,为了使我们的权重系数W变化从而取得最好的分类结果https://www.zhihu.com/question/52398145 有详细解释损失函数。
9.softmax loss softmax直白来说就是将原来输出是3,1,-3的分数通过softmax函数一作用(先指数化,在归一化),就映射成为(0,1)的值,而这些值的累和为1(满足概率的性质),那么我们就可以将它理解成概率,在最后选取输出结点的时候,我们就可以选取概率最大(也就是值对应最大的)结点,作为我们的预测目标!我们用softmax loss对分数进行转化处理并得到正确的类别的损失函数是-log P
交叉验证 超参数
线性分类
损失函数
Piazza
Google Calidate
Google Cloud
CV的挑战:
1IIIumination
2 Deformation
3 Occlusion
4 Clutter
5 Instraclass Variation
线性分类学习图片在一个高维空间线性决策边界问题,高维空间对应了图片能取到的像素密度值
数据驱动方法
交叉验证
SVM Loss Function: Hinge Loss
Sum(Max(0, Sj - Sy+1))
Sj 是预测的分数
强化学习的优化方式类似SVM,只关注正确分类的分数,而且不需要分数是否可导
Loss Fuction的意义:
量化不同的错误到底有多坏,模型不再范类似的错误
奥卡姆剃须刀:选择最简单的
通过分析SVM损失函数,来解释其他所有的损失函数
在线性分类器中,W是一个分类模板,体现了所有训练数据的经验知识,而W是通过训练过程得到的;线性分类的过程很简单, 当输入一张图片,将此图片拉长成一个三维长向量,乘以参数矩阵W,得到所有分类的评分,某一类的得分最高,就将此输入的图片分为哪一类。如果某一类的得分很低,那么就表示输入为此类的概率很小。当W的值不同的时候,得到的分类分数也不同,要使得分类正确的概率最高就需要选择最佳的W,那么就需要损失函数。损失函数是所有样本的预测分数与实际分数的差的平均值。

在两类SVM中,分类类别为正例和反例。

在这个例子中,输入为猫的损失函数为:Li=max(0,5.1-3.2+1)+max(0,-1.7-3.2+1)
在SVM中,损失函数在所有错误分类的分数小于正确分数分类的分数,或者正确分类的分数超过错误分类的分数一定的边界,则定义损失函数为0;如果错误分类的分数大于正确分类的分数,那么损失函数就是所有样本错误分类的分数的平均值。Sji为正确分类的分数;此函数就像一个合页。随着正确分类的分数增加,其损失函数越低。损失函数的值最小为0,最大为无穷大。在最初训练的时候,我们会初始化W的值。如果所有的分数都差不多,当使用多分类SVM时,那么损失函数将会是分类类别-1;因为所有的错误分类数为c-1,损失函数就存在c-1个为的边界。损失函数如果不使用求和而使用平均值的话其最终的值是没有差别的。如果算上所有的类别, 那么损失函数加上1.
代码例子:

那么有一个问题是当损失函数为0的时候,其W是不是唯一的呢?当然不是唯一的。
但是分类器的目的不是在为了拟合训练数据,而是如何在测试数据上有好的效果,因此我们在损失函数上加了一项正则项,使得模型更加简单,可以在测试数据上有更好的表现。
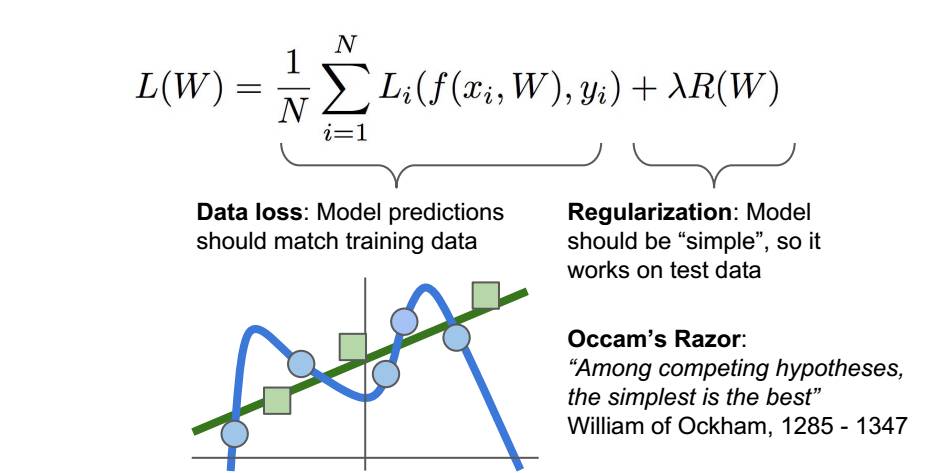
超参数是为了平衡这两项。在实际训练中,对于模型的训练时间影响很大。
加入正则化主要目的是为了防止模型过拟合,过拟合就是模型在训练数据上的表现很好,但是在测试数据上表现很差的现象。模型为了拟合所有的训练数据,w就看一取任意值变得很不稳定。加入了正则项就是给W加了先验知识,使得模型简化,避免过拟合。
正则化一般有两种,L1范数和L2范数。
which W will be best——loss fuction
x-the input to the algorithm
y-the label or predict
L=sigm[Li(f(xi,w),yi)/N]
different loss functions:
iii
损失函数是N个样本的平均。
一般情况下,采用均方误差。
损失函数是对权重w好坏的评价,损失函数越小,说明网络学习的权重W越好。
正则化的作用是用来鼓励网络采用更简单的模型来描述,也就是我们常见到的奥卡姆剃刀原则。(或者说起到一种降幂的作用,降低模型的复杂度,而不是去拟合模型,拟合的过分了也就出现了过拟合的现象,我想正则化应该就是起了这样的作用)
常见到的正则化是
L1:很希望大部分的W元素都是0,只能有少量的元素偏离0(虚幻稀疏解),所以他更多的是在考虑0的或者非0元素的个数。
L2:权重衰减项,考虑W的整体分布,让所有元素具有较小的复杂度。
其实dropout和batch nomalization都是现在很火的实现正则化的方法。
多分类的SVM损失函数
softmax损失函数
cross entropy就是softmax function????

 客服1
客服1
 官方群
官方群