



计算图表示一个函数:
节点表示操作
求取计算图中变量的梯度
链式法则求取
上游梯度和本地梯度
梯度值累加
列举了两个例子
变量梯度的大小和变量的大小一致,也就是帝梯度的维度与变量是相同的。
¥
支付方式
请使用微信扫一扫 扫描二维码支付
请使用支付宝扫一扫 扫描二维码支付
计算图表示一个函数:
节点表示操作
求取计算图中变量的梯度
链式法则求取
上游梯度和本地梯度
梯度值累加
列举了两个例子
变量梯度的大小和变量的大小一致,也就是帝梯度的维度与变量是相同的。
Piazza
Google Calidate
Google Cloud
CV的挑战:
1IIIumination
2 Deformation
3 Occlusion
4 Clutter
5 Instraclass Variation
线性分类学习图片在一个高维空间线性决策边界问题,高维空间对应了图片能取到的像素密度值
数据驱动方法
交叉验证
SVM Loss Function: Hinge Loss
Sum(Max(0, Sj - Sy+1))
Sj 是预测的分数
强化学习的优化方式类似SVM,只关注正确分类的分数,而且不需要分数是否可导
Loss Fuction的意义:
量化不同的错误到底有多坏,模型不再范类似的错误
奥卡姆剃须刀:选择最简单的
通过分析SVM损失函数,来解释其他所有的损失函数
记号:
X输入样本 32*32*3 = 10*3072
F 10*1
W权重 Parameters, Weights 3072*1
线性是指的是单层神经网络,而不是真的线性,在图像中提取了背景虚化的类别,RGB的区分
K-Nearest Neighbor在图像处理的几个问题
1 欧式距离不能处理Boxed Shifttd Tinted
2 Curse of dimensionality维度灾难
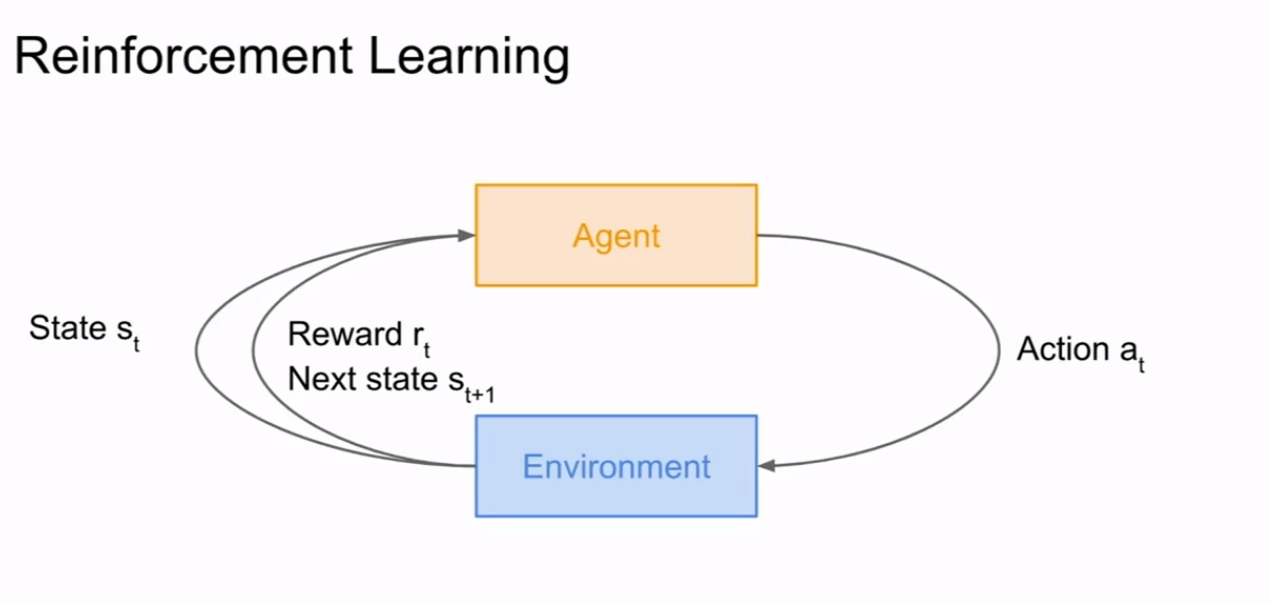
通过一个代理和环境进行交互执行一系列行动,通过这些行动可以获取最大的奖励(学习如何获取到最大的奖励)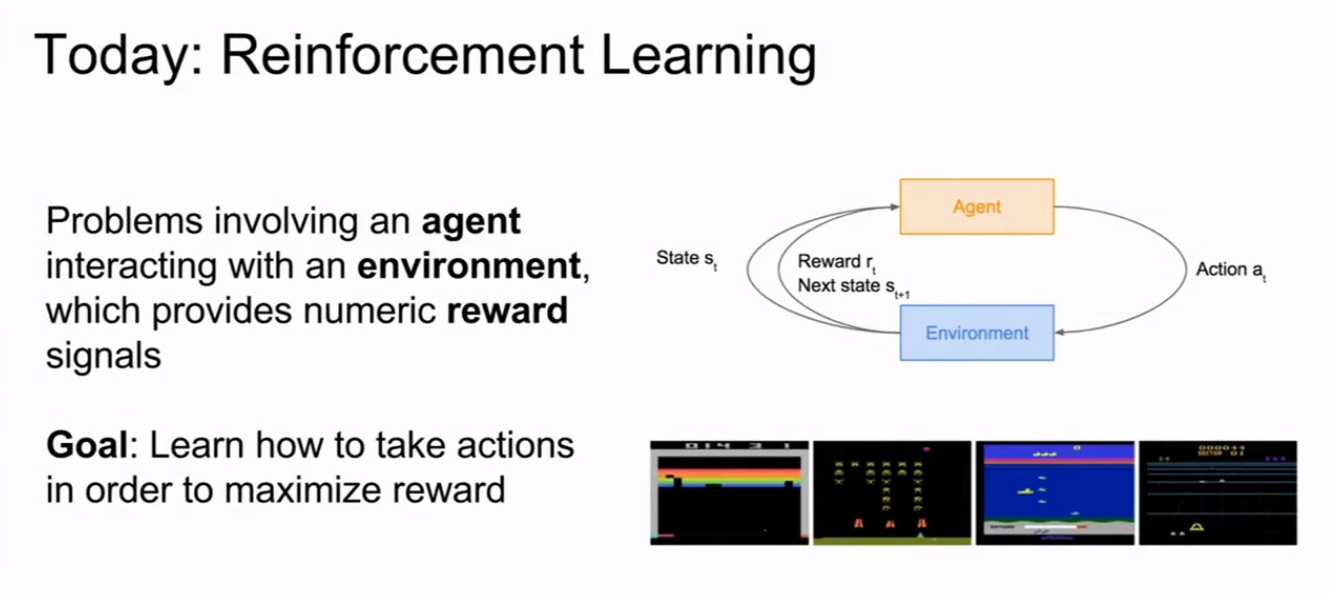
环境给予代理一个状态,代理根据这个状态执行相对应的动作,然后环境给这个动作一个奖励(该奖励为正时为奖励,为负时代表惩罚)然后环境会给予代理下一个状态循环往复,最后从中学会一个策略对环境给出的状态能够得到一个好的结果。
马尔可夫决策过程(Markov Decision Process)
当前状态由四个参数决定如下图所示,来自课程截图

决策过程:
1.在第一步初始化当前状态s0和当前状态的概率P0.
2.循环以下行动直到完成训练:
2.1 Agent(代理)从动作集合中选择当前一个动作应用于当前状态
2.2代理执行动作后环境给出一个评价对应当前的状态和动作(告诉代理它做的对不对,给出惩罚或者奖励)。
2.3环境生成下一步的状态(由当前状态和动作得到一个概率,该概率用来生成下一步状态)
2.4代理接收到奖励和下一步的状态,准备进入下一次循环

Bellman equation
通过执行一些行动我们可以得到一个最大期望的Q值,通过迭代来达到一个收敛值。缺点:不可扩展,对于每一个状态都需要进行一次计算,计算量大。


加油字幕君你是最棒的
邻近算法
linear classification
The difference between KNN and neural network:
In KNN, there is no parameters
In neural network, we are going to summarize our knowledge of the trainging data and stick all that knowledge into these parameters——W.
Linear classifier:
f(x,W)=Wx
KNN
L1distance(Manhattan):depends on the choice of coordinates system, when changing the coordinate frame, that would actually change the L1 distance between the points.
L2distance(Euclidean): it's the same thing whatever the coordinate frame is.
For the input features, if the individual entries in the vector have some important meaning for the task, then L1 may fit.
But if it's just a generic vector in some place, then the L2 maybe more natural.
In KNN, there are two major choices that we should select:
the K value
the distance metric
hyperparameters:the choices about the algorithm that we set rather than learn:
How do you actually make these choices for your problem and for your data?
setting hyperparameters:
which W will be best——Optimization
learning rate
SGD-at every iteration ,we sample some small set of training example,which name is minibatch
Image Feature:
to train a classifier, we should compute various feature representations of that image, that are maybe computing different kinds of quantities relating to the appearance of the image, then concatenate these different feature vectors and then input the classifier.

 客服1
客服1
 官方群
官方群