



knn K nearest Neighbors k个最最临近的值
两种位置的计算方法:
曼哈顿距离与欧顿距离
超参数
选择超参数的方法:
给出训练集
验证集与测试集
在最后去使用测试集去验证
验证集与训练集可以轮流交叉选取。
KNN训练简单,只需要记录信息即可。
但测试时时间太长
不太好:
1.计算距离的方式,不太适合图像的表达
2.维度越高,需要的训练数据越多,但我们并没有这么多训练数据
¥
支付方式
请使用微信扫一扫 扫描二维码支付
请使用支付宝扫一扫 扫描二维码支付
knn K nearest Neighbors k个最最临近的值
两种位置的计算方法:
曼哈顿距离与欧顿距离
超参数
选择超参数的方法:
给出训练集
验证集与测试集
在最后去使用测试集去验证
验证集与训练集可以轮流交叉选取。
KNN训练简单,只需要记录信息即可。
但测试时时间太长
不太好:
1.计算距离的方式,不太适合图像的表达
2.维度越高,需要的训练数据越多,但我们并没有这么多训练数据
机器视觉算法的来源:
图像在计算机上的存储是一个矩阵,你并不知道什么样的矩阵对应着什么样的图像。
1.相同的图像在不同的角度上矩阵完全不同,不同的视角
2. 不同的关照
3.图像的变形,背景
4.物体本身的动作
思想的转变:
旧:输入一张图片,返回具体的信息。旧有的传统的算法,建立在你可以枚举所有可能性的前提下。
旧方法:物体的特性,比如猫有眼睛,鼻子。然后计算图像的边缘,统计边,角,通过这些规则来识别到猫的存在
旧算法缺点:1,实际效果不是很好,2.更改识别内容,等于重新来一遍
新:使用数据驱动的算法,我们写的算法并不是去识别这个物体而是去通过大量的数据去生成识别到此物体的模型 或者说函数
numpy
向量化操作
线性分类器
k-means
svm
图像分类:
把图片与标注统一起来
思想的转变:
以前的思想:输入一个图片,识别他是以是什么,输出
现在的思想:输入一堆图片,得到一个模型 training函数
然后是一个预测函数,接受一个模型和一个图像,输出预测。
CIFAR10数据集
分类任务:
1.训练函数:输入数据 标签,输出模型
2.预测函数:输入模型,输出结果
原始草图
边缘,曲线
组合
有简单的形状,由通用形状组合到一起
线与边缘
图像进行分割,把有人的像素点提取出来
过拟合是瓶颈,维度太多,太复杂。
卷积神经网络 CNN model
重要性。
数据量大
标注
推荐
Manhattan distance
Euclidean distance
交叉验证在小数据集上应用更多,深度学习中不常见
维度灾难
K最近邻算法
图像分类
谷歌云
python3 numpy
api
edges
conners
not good
最近邻:fast train, slow training
cifar-10
曼哈顿距离
K最近邻
多类别 SVM loss
1.Q:如果轻微的改变汽车的分数,会发生什么?
A:不发生改变
2.Q:SVM的损失最大值,最小值?
A:最大:无穷,最小:0
3.Q:当所有分数S都差不多均匀分布,近似于0,且差不多相等,SVM的损失预计会如何?
A:损失近似于类别数C-1,(在刚刚开始训练第一次迭代时,初始化的W值很小,此时的损失应近似于C-1,是一个有用的debug方法)
4.Q:如果在损失中将所有的类别分数值加起来(包括j = y_i),会如何?
A:损失增加1(不包括时使分类正确时损失为0,更符合直观感受)
5.Q:如果使用mean而不是sum,会如何?
A:不会发生改变,取平均只是把结果进行了固定比率的缩放,对结果不发生影响
6.Q:如果使用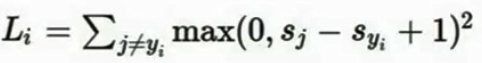 ,会如何?
,会如何?
A:这是另一种计算损失的方法,在具体的问题中,可能会有应用
Softmax loss
1.Q:L_i的最大最小值?
A:最小:0 最大:无穷
2.Q:初始W很小时,所有的S都近似于0,此时的loss?
A:L_i=log C
视觉识别问题
图像分类
目标检测 object detection
action classification
图像摘要image captioning 描述图片
CNN convnets
2010 NEC UIUC
2012 SuperVision Hinton 7层神经网络 Alexnet
2014 GoogLeNet VGG 19层
2015 MSRA 152 ResNet 残差网络 微软研究所
CNN 1998 Yann LeCun 贝尔实验室 数字识别
pooling 池化
卷积层 下采样 全连接层
增大算法规模 增加数据 互联网
挑战 语义分割 semantic segmentation
知觉分组 perceptual grouping
理解图像中的每个像素
3D理解 由图片重构世界
动作识别 activity recognition
增强现实 虚拟现实
把图片作为一组语义的集合 对象关系 属性
场景中的动作
500ms内 人类视觉描述了图像
医学诊断 自动驾驶
DeepDream NeuralStyle GAN?
从零开始实现CNN使用Python
完整实现正向传播 反向传播
从框架实现 tensorflow torch caffe
使用RNN 的图片摘要
风格迁移
图像分类-数据驱动犯方法
8. First clssifier:Nearest Neighbor
def train(images, labels):
# Machine learning!
return model
def predict(model, test_images):
# Use model to predict labels
return test_labels

 客服1
客服1
 官方群
官方群