



¥
支付方式
微信支付
支付宝支付
¥
请使用微信扫一扫 扫描二维码支付
¥
请使用支付宝扫一扫 扫描二维码支付
视觉
目标分割
boosting
Adaboost SIFT特征
过拟合
wordnet
imagenet
一、挑战
1、同一物种,拍照角度不同,像素矩阵不一致;
2、遮挡问题
3、背景混乱问题
二、 数据驱动方法
1、收集图片和标签数据
2、训练机器学习分类器
3、评估分类器效果
三、常用数据集
CIFAR10,10个类别,每个类别5万个样本。
四、KNN
1、曼哈顿距离:矩阵中对应位置元素进行相减最后求和。
2、KNN训练复杂度
测试慢O(N)训练快O(1)。
3、KNN使用委员会选举法进行类别鉴定。
卷积神经网络的工作原理
全连接层:在向量上操作
对于图片,将像素展开成向量
对向量进行点积运算得到一个数,就是得分
卷积层:
卷积核
和特定空间的值进行点积计算
卷积核的工作:在图像上滑动,遍历每一个像素
卷积层的底层一般是比较初级的特征,越深层得到的一些更加复杂的图像特征
Q:卷积核滑动时,有些像对边缘或拐角的采样而不是其他地方
Q:可视化图像中是什么
网格中的每个部分都是一个神经元,可视化的部分就是输入是什么时将特定的神经元的激活函数最大化
卷积:图像-卷积层-非线性函数-采样层-全连接层-分值函数
卷积神经网络:
不同的是在训练的时候需要训练卷积层
1.历史
1986 backpropogation
2006 hinton DNN
需要谨慎的初始化才可以完成反向传播
方法:预训练(对每一个隐藏层用玻尔兹曼机来建模,通过迭代训练每一层来得到初始化的权重,再反向传播,调整参数)
神经网络的发展
1950s 猫眼神经测试
1980神经认知机
1998 lenet5
2012 AlexNet
CNN 用于检测,分类,人脸识别,视频,姿势识别,游戏
描述图片
Justin(图像着色代码)
1.对全连接层而言,我们要做的就是在这些向量上进行操作,比如我们有一张图片,三维图片,32*32*3大小,我们将所有的像素展开,就可以得到一个3072维的向量,我们得到这些权重,把向量与权重矩阵相乘,这里我们用10*3072,然后就可以得到激活值,这一层的输出,例子中我们用十行数据与这个3072维的输入进行点积运算,从而我们可以得到一个数字,这个数字就是该神经元的值
2.至于卷积层,他和全连接层的主要差别就是可以保全空间结构,这个三维输入的结构,我们的权重是一些小的卷积核,例子中是5*5*3的大小,我们将把这个卷积核在整个图像上滑动,计算出每一个空间定位时的点积结果,接下来就是他们工作的具体细节
3.首先,我们采用的卷积核,总是会将输入量扩展至完全,所以她们都是很小的一个空间区域,他们会遍历所有通道,然后我们采用这个卷积核,在一个给定的空间区域,在这个卷积核和图像块间进行点积运算,我们要做的就是在图像空间区域上,覆盖这个卷积核,然后进行点积运算,也就是将卷积核每个位置元素和与之对应图像区域的像素值相乘,这个区域是从图像上取出的,经过运算后给我们一个点积结果,例子中我们进行了5*5*3次计算,之后我们再加上偏置项,这就是卷积核W的基本方法,就是用W的转置乘以X再加上偏置项
4.我们如何滑动卷积核并遍历所有空间位置? 将这个卷积核从左上方的边角处开始,并且让卷积核遍历输入的所有像素点,在每一个位置,我们都进行点击运算,每一次运算都会在我们输出激活映射中产生一个值,之后我们再继续滑动卷积核,最简单的方法是一个像素一个像素的滑动,我们持续进行这样操作,并相应的填满我们的输出激活映射。
5.当我们在处理一个卷积层时,我们希望用到多种卷积核,因为每一个卷积核都可以从输入中得到一种特殊的模式或者概念,所以我们会有一组卷积核,这里我们将利用第二个卷积核,也就是图中绿色的卷积核,也是相同的大小,将它进行滑动,遍历所有像素,得到第二个相同大小的绿色的激活映射,我们可以按照相同的方法使用多个卷积核进行计算,就会产生多个激活映射
6.在卷积神经网络中我们是如何使用卷积层的? 我们的ConvNet基本上是由多个卷积层组成的一个序列,他们依次堆叠,就像我们之前在神经网络中那样堆叠简单的线性层一样,之后我们将用激活函数对其进行逐一处理,比方说一个ReLu激活函数,我们将得到一些比如Conv和ReLU的东西,以及一些池化层,之后你会得到一系列的这些层,每一个都会有一个输出,该输出又作为下一个卷积层的输入
7.前面的几层卷积核一般代表了一些低阶的图像特征,比如说像一些边缘特征,对于那些中间层,你可以得到一些更加复杂的图像特征
8.实际上,当你给他这种类型的层次结构并使用反向传播进行训练,这些类型的卷积核也会学习到特征
9.卷积神经网络整体上来看,其实就是一个输入图片,让它通过很多层,第一个是卷积层,然后通常是非线性层,所以ReLU其实就是一种非常常用的手段,我们有了Conv ReLU 接下来我们会用到池化层,这些措施已经大大降低了激活映射的采样尺寸,经过这些处理后,最终得到卷积层输出,然后我们就可以用我们之前见过的全连接层连接所有的卷积输出,并用其获得一个最终的分值函数
10.我们将卷积核滑过每一个单独的空间位置,每滑一次所经过的区间,称其为步幅,在最初我们是用1作为步长,会产生一个5*5输出,如果我们采用值为2的步幅,我们总共会有3个可以拟合的输出,也就是一个3*3的输出
11.如何计算输出尺寸? 假设输入的维度为N,卷积核大小为F,那么我们在滑动时的步幅以及最终的输出大小,也就是每个输出大小的空间维度,这些将变成(N-F)/步幅+1
12.深度就是使用卷积核的数目 零填补是否在角落上增加了一些额外的特征,我们尽全力来得到一些值,然后做一些处理那个图像范围的事,所以零填补是它的一种方式,我们可以侦测到在这个区域内的模板的某些部分,所以在边缘处是有些人为成分,你可以尽最大努力来解决它
13.为什么做零填补? 我们做零填补的方式是保持和我们之前的输入大小相同,我们开始用的是7*7,如果让卷积核从左上角处开始,将所有东西填入,那么我们之后会得到一个很小的输出,但是我们想保持全尺寸输出,就会做零填补
14.如果你需要处理的图像是多层叠加在一起的,你会发现,如果你不做零填充,或任何形式的填充,输出图像的尺寸会迅速减小,这不是我们想要的,设想你有一个不错的深度网络,你的激活映射迅速缩的非常小,这样是不好的,因为这会损失一些信息,你只能用很少的值来表示你的原始图像
Nearest Neighbour是K-nearest Neighbour 中K=1情况。分类效果往往不好,所以一般会给K赋一个稍大的值以取得更好的分类效果。
(1)K-Nearest Neighbours选择Distance Metirc(距离度量)
1. L1(Manhattan)distance
像素之间绝对值的总和
2. L2(Euclidean)distance
取平方和的平方根。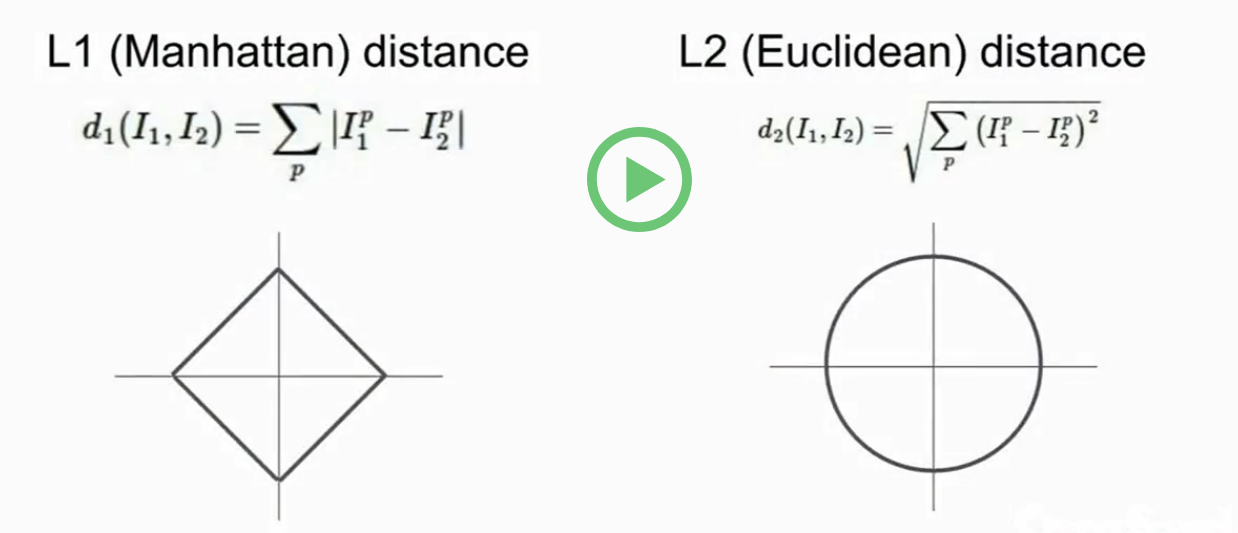
hyperparameters(超参数):是自己设置而不是学习到的。不同的问题有不同的超参数。
例子:上述的K值和距离度量方法都是超参数。
在实际应用中,knn是不会被采用的:
(1)因为测试的时间非常慢(我们期望测试快)
(2)像素的距离度量不是那么有用的信息(L2距离不能很好的衡量图像的相似性)
(3)会产生维数灾难
Problem:Semantic Gap(语义鸿沟)
Challenges:
(1)Viewpoint variation(视角不同,照相机换了个角度拍,计算机看到的像素矩阵中的像素值就会完全不一样)
(2)Illumination(照明问题,图片的光线明暗)
(3)Deformation(变形,比如猫会以不同的姿势呈现在图片中)
(4)Occlusion(遮挡问题,只能看到物体的一部分)
(5)Background Clutter(背景混乱,物体颜色和背景颜色相近)
(6)Intraclass variation(类内差异,一张图里可能有多个不同形态的同种物体)
Classsifier:
(1) Nearest Neighbour
def train(images, labels):
# Machine learning
return model
def predict(model, test_images):
# Use model to predict labels
return test_labels
我们希望训练的过程较慢(因为训练一般数据中心训练,可以负担非常大的运算量)以训练出一个优秀的分类器。而希望预测过程可以很快,让他运行在手机,浏览器等低功耗设备上,并且运行的很快。
而Nearest Neighbour 的表现恰恰相反,训练快,预测慢。所以是比较落后的方法。

Loss function:
f(x,W) = Wx+b
度量任意某个W的好坏的方法
用一个函数把W作为输入,看一下得分,定量的估计W的好坏。这个函数被称为损失函数。
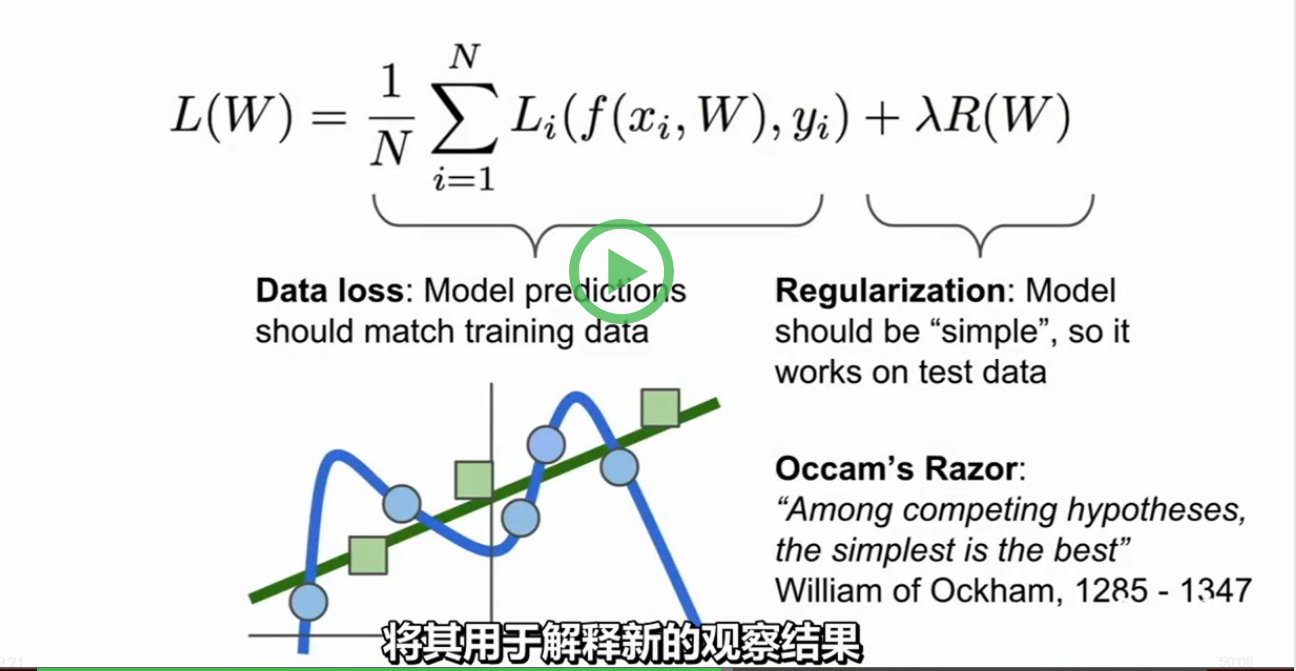
分类器会追求拟合训练数据,但实际上我们并不关心在训练数据的表现好不好,我们只关心在测试数据上表现的好坏。在拟合训练数据时,会拟合成如上图蓝色曲线一样的情况,在新数据(绿色方块)加入时,就完全匹配不了,其实我们需要的是绿色的线。这时,在损失函数后面加一项正则项会使模型变得简单一些。
这时损失函数就有了两项,数据丢失项和正则项,然后用一个超参数 λ 来平衡这两个项。
相关课程

未来汽车大讲堂——智能驾驶第一课
¥399.00
¥599
会员¥258
开课日期:直播已结束,可回看开始
从Python入门-如何成为一名AI工程师
¥299.00
¥499
会员免费
开课日期:开始
授课教师
暂无教师
微信扫码分享课程
 客服1
客服1
 官方群
官方群