



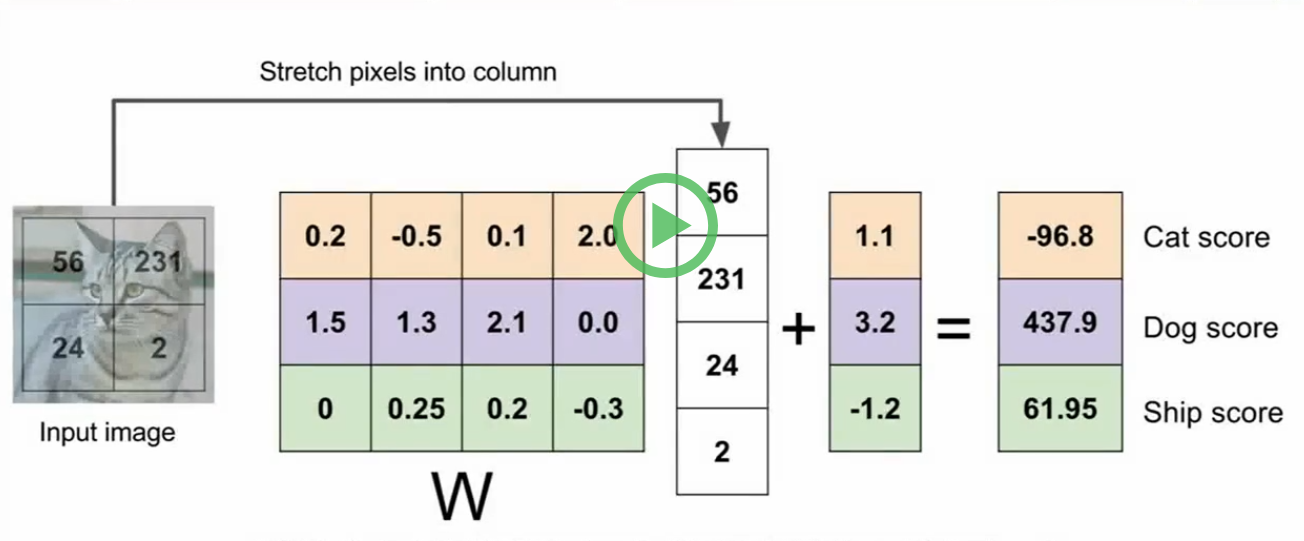
线性分类器Linear Classifier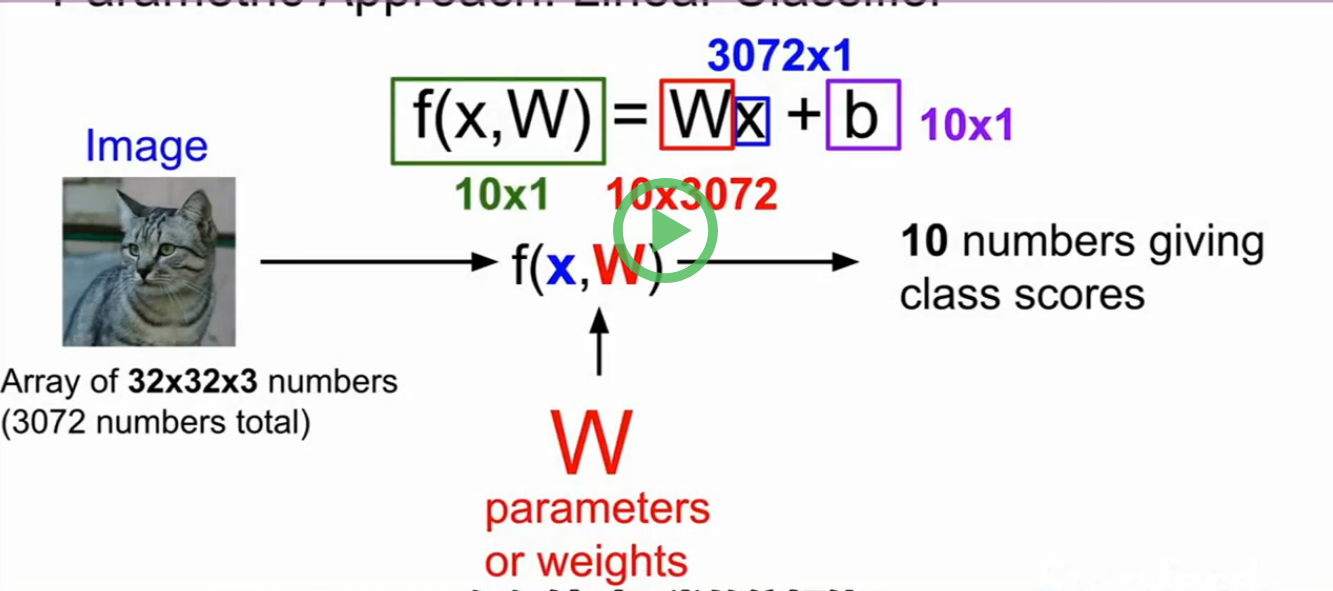
¥
支付方式
微信支付
支付宝支付
¥
请使用微信扫一扫 扫描二维码支付
¥
请使用支付宝扫一扫 扫描二维码支付
pooling操作时没有参数的!!!只是简单的提取每一块的最大值。
1*1的卷积可以帮助减少计算的复杂度
googlenet就是由inception模块级联而成。没有全连接层。
宽度,深度,残差
dense block---dense connected convolutional natework
网络效率将是我们一直努力的方向
dropout 一般用在全连接层
dropout在卷积层也会用到,他是随机的把整个特征映射置0,举个例子输出通道的几个通道置0,而不是简单的几个元素
在训练集上使用dropout会使得训练的时间变得很长,但是同时他的鲁棒性会增强。
采用BN之前我们的损失函数对权重更新的一点小变化都很敏感,导致学习不到很好的结果(优化)。
但是使用了BN,我们的损失函数对权重变化就没那么敏感,所以也就能更好的学习(优化)。
批量归一化处理(bn):
为什么我们想恢复这个恒等变换(恒等映射),有什么意义??(为了让他学习参数??)
因为我们想要数据具有灵活性,将数据转换为高斯数据分布,(貌似高斯分布就具有灵活性)(有点强制转换的意思)
高斯化:(当前值-均值)/方差,先将数据移到原点(平移变换),再进行尺度缩放,得到单位高斯分布。
babysitting the learning process(观察学习处理)
当你得到cost基本没啥变化的时候,那么说明你的学习率太低了。。(尝试增加学习率)
但是当你cost值一直为nan,说明你的学习率太大了。之歌时候你要尝试减小你的学习率
超参数的选择:
采用交叉验证策略
激活函数relu更符合神武神经元的特性。
2012年赢得image net大赛的alexnet就是使用了relu
relu在负半轴的时候会出现梯度消失的情况,我们称之为dead relu--- will never activate
数据预处理:
0均值化
归一化
白化
权重初始化:我们一般采用截断正态分布
经验表明:Xavier初始化也是一个不错的选择。
如果直接设置所有的权重初始化为0,那样你的所有神经元得到的输出是一样的,梯度更新的结果也是一样的,总之你的所有神经元学习到的结果是一模一样的,但是你的目标是想要神经元学习到不同的特征,那样你才能获得比较合适的结果。
初始化我们可以采用很小(权值初始化很小)的随机数。---效果不好,梯度为0,得不到更新。
如果初始化为1(权值初始化太大)那么整个网络会饱和
AdaBoost:人脸识别
目标识别:SIFT特征:思路:匹配整个目标
目标识别的首要任务是在目标上确认这些关键的特征,然后把这些特征与相似的目标进行匹配,它比匹配整个目标要容易很多。
cs131:基础课
cs224n:深度学习和NLP
cs231n:这门课,深度学习和CV
cs231a:更全面的CV讲解
pooling的作用:是为了使我们获得更少的参数,减小图片的尺寸在一定程度上就是减少了网络的参数。
pooling操作,我们只会简单在平面上减少尺寸,不会改变输入输出通道的个数。
pooling的过程应该没有任何的overlapping,也就是重叠的情况。、
最大池化的意义是再局部区域内找到显著性水平最明显的一个。
在神经网络中,我们先输入一张图片,经过第一层卷积后可以得到32张(或者不管多少张feature map),这32张的每一张都是通过一个3*3的卷积核来做卷积操作的,我觉得这样的操作经过了32次,每次这个3*3的卷积核里面的数值会发生改变!!!!!(这个理解不太对)
不对,如果我输入channel=1,输出channel=32,那我会初始化出32个卷积核,并行操作运行得到这32张feature map.
输入一张图经过前几层卷积,我们会得到比较loe_level features(这些特征很弱,或者说是不具有代表性。)---然后再经过几层神经网络,我们会得到mid_level features(得到的这些特征可能会能体现出我输入图片的一些特征了,但是可能还不能够完全表示)---再经过几层神经网络,我们能提取出high_level features(这些特征很有可能能代表我输入图片的特点或者而说是属性)---最后可以通过线性分类器来进行分类。。。
很重要的一点,正是由于神经网络的这些特点,我们才可以做transfer learning,直接保存前几层输出的feature,然后将这个训练好的网络进行fine-turning,加上新场景的图片输入------
神经网络再寻找什么??----显然是图像的特征????
做padding的原因:是想获得和输入尺寸一样的大小的输出图片。
输入32*32*3的图片经过5*5*10的卷积核,请问这个网络中含有多少个参数??
5*5*3+1=76(这里的1是偏置)
76*10=760个参数
相关课程

未来汽车大讲堂——智能驾驶第一课
¥399.00
¥599
会员¥258
开课日期:直播已结束,可回看开始
从Python入门-如何成为一名AI工程师
¥299.00
¥499
会员免费
开课日期:开始
授课教师
暂无教师
微信扫码分享课程
 客服1
客服1
 官方群
官方群