


2015年11月5日,google翻译系统进行了一次大整改,翻译系统的翻译水准几近人类的翻译水平。
深度神经网络除了在翻译上有提升外,在实时图像切割也有很大的帮助。另外alphaGo在围棋比赛上战胜人类...
天文,医疗等等都可以在AI上获得好处。(以上是深度学习的相关背景)
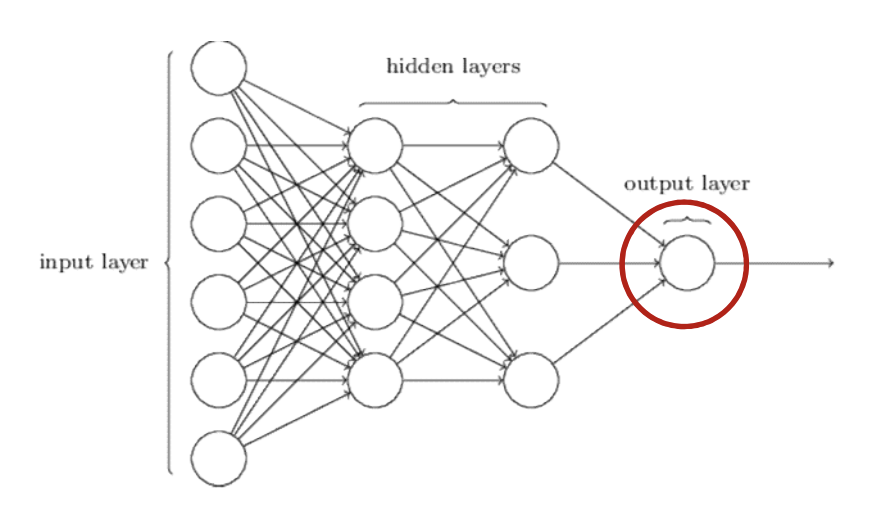
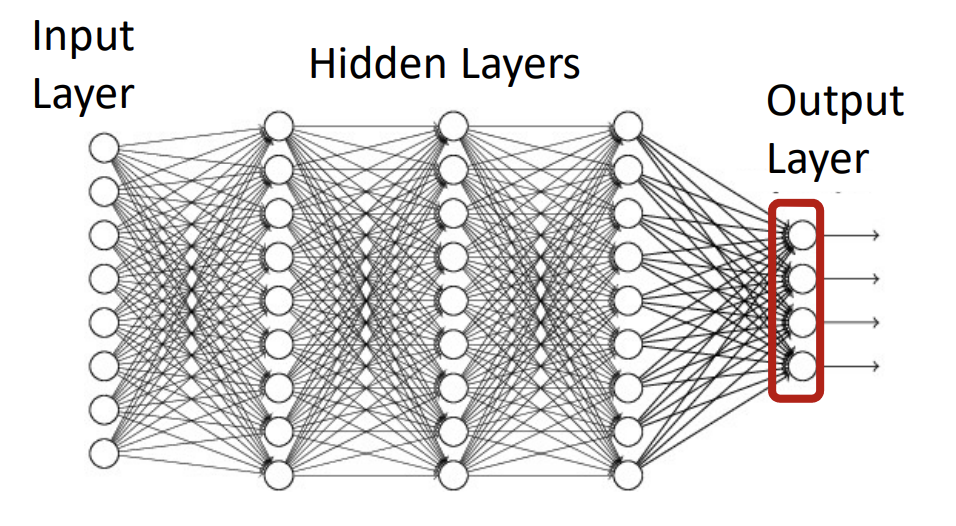
学习清单:
- 了解什么是神经网络
- 怎么建构神经网络
- 熟悉这个东西
- 运用神经网络
课程的网址是:deeplearning.cs.cmu.edu
CMU的学生很神,如果课程很简单,很容易通过,他们反倒不会选择这堂课(所以挂科比较爽?虽然有挑战确实比较有意思,可是也要面对风险)
我们大脑的神经网络靠神经元来连接。
以前有个人说大脑里有50亿的神经元协助大脑运转,被世人嘲笑,后来他就道歉说自己错了,然后就死了。
现在我们知道他是错了,不是50亿而是有180亿。
(所以聪明的人从来不是聪明人的手下败将,而是被愚钝的人手刃)









 客服1
客服1
 官方群
官方群