


线性特质:
f(ax+by) = af(x) +bf(y)
f(x)=西格玛求和xi+b,b不为零时,不过原点。
阈值使用激励函数进行平滑0,1的输出,比如sigmod,tanh,rl等函数。
多层感知机作为一个通用的布尔函数,作为一个通用的分类器,作为一个通用的函数模拟器。这些机制在前面已经提到,深度学习的机制从这里展开。
首先是布尔函数的表达,单层表达布尔开关,多二层(一层隐藏层)表达所有的布尔表达式。如图:
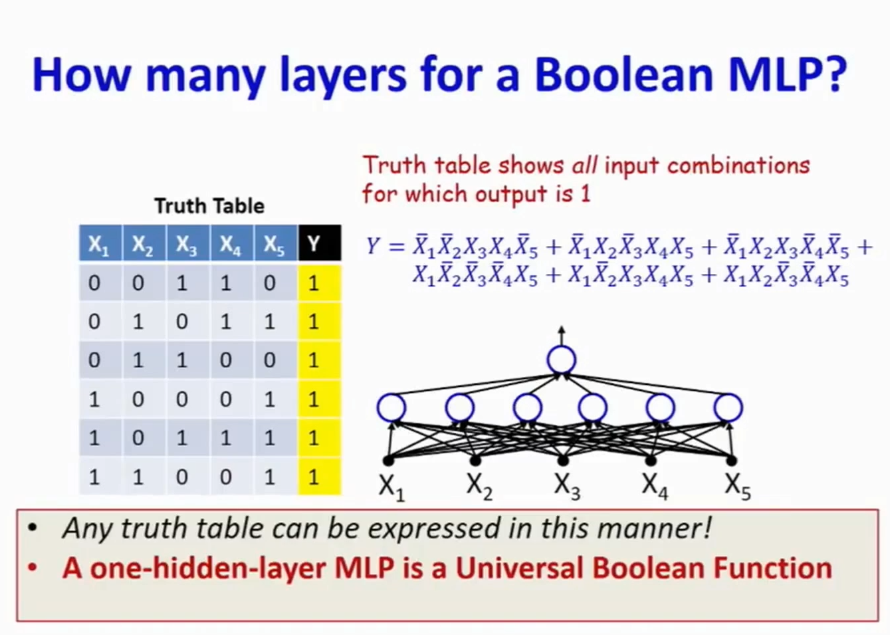
其中每个真值表里的真值可以用析取范式表达,而每个析取范式可以在隐藏层中的某一个节点与输入(x1到x5)的链接表达。因此两层足够表达表结构。而隐藏层的感知节点数通常在最坏情况下是为2的n-1次方,n为输入量,是指数关系。这时需要加深层次去削减节点,n个输入的异或操作使用3(n-1)个节点就可以了,而层数为2log2N。这里就需要对层数和节点数做个权衡,这里并不是那种深度固定的问题。
Karnaugh Map优点:
1、用Grid的形式来表示真值表,第一眼看起来很直观。
2、每个相邻的格子之间的只有一个bit位的差别。
3、简化了析取范式。
- 如果用最基本的析取范式(DNF)来表示,则需要7个表达式(每一个高亮的格子都需要一个表达式,例如0000,表示为XYZW,再将其7个表达式组成析取范式)。
- 如果用Karnaugh Map,运用Group组合,由第一列可以看出来,当YZ为00的时候,WZ的值不会影响真值(Truth Value)。此时四个表达式可以简化为一个。

4、在第一层可以减少Neuron神经结点的数量。可以减少到3个神经元。
Karnaugh Map缺点:
1、在Karnaugh Map中找到最紧凑的Group组合是一个NP难的问题。
2、(Worst Case)当表示为一个棋盘格的时候,Karnough Map所需要的Neuron神经结点是最多的。下图需要8个单元。

Karnough Map 三维 6个变量的特性:
1、由4 x 4 x 4 =64 个小立方体组成,每一个立方体代表一种表达式,一种可能性。
2、Worst Case需要 8 x 4 = 32 个 Neurons。总结:2^(N-1)(指数型)

XOR 特性:
1、交换律。
2、结合律。

简化版的XOR运算只需要2个神经元。

每一个XOR运算可以只用3个神经元表示。这样将神经元数量由指数型降到了线形。2^(N-1) -> 3 x (N-1)。运用XOR的结合律可以讲,深度从N -> log(n)。






 客服1
客服1
 官方群
官方群