


1、强化学习本质上就是给出了一种可以处理决策的数学框架
2、将神经网络与强化学习结合,TD gammon就是结合两者得到一个价值函数。变换的算法是拟合值迭代
3、端到端学习:需要高层次的抽象
4、 深度强化学习的挑战:奖励函数到底是什么样子的
模仿学习
预测,学习机制以及简单规则的定义
如何突破策略游戏
循环神经网络-》记忆性强化学习
¥
支付方式
请使用微信扫一扫 扫描二维码支付
请使用支付宝扫一扫 扫描二维码支付
1、强化学习本质上就是给出了一种可以处理决策的数学框架
2、将神经网络与强化学习结合,TD gammon就是结合两者得到一个价值函数。变换的算法是拟合值迭代
3、端到端学习:需要高层次的抽象
4、 深度强化学习的挑战:奖励函数到底是什么样子的
模仿学习
预测,学习机制以及简单规则的定义
如何突破策略游戏
循环神经网络-》记忆性强化学习
第一讲中展示的深度强化学习在机械手控制、供应链管理、交通协调方面的示例对我的启发很大,之前我认为解决大系统问题最好是将大系统的所有规律方程都列出来,然后为一个目标求出一个解,但是可能有的时候求出一个全解,需要的计算量可能满足不了。这里给系统中每个个体都有一个强化学习的自主能力,通过训练,最后每个个体遵从它在与环境交互过程中学习到的规则达到了整个系统的协调。这类似于群智能算法,群智能算法要设定每个个体的规则,然后每个个体按照其设定的规则迭代最终寻到较优解。而这里应用深度强化学习所能够学习到的规则是在于环境交互中学到的。
Learning as the basis of intelligence
deep reinforcement learning
a.from supervised learning to decision making
b.model_free algorithms
c.advanced model learning and prediction
exploration
d.transfer and multi-task learning, meta-learning
what is reinforcement learning?
adapt
deep learning helps us handle unstructured environments.(不断变化的)
reinforcement learning provided a formalism for behavior.
interaction between agent and environment
decisions(actions)-consequences(observations\rewards)
end-to-end learning
robotic control pipeline:
obserations-state estimation-modeling prediction-planning-low-level control-controls
problems:
beyond learning from reward
maximizing rewards
advanced topics: inverse reinforcement learning, transfer learning
where do rewards come from?...
Are there other forms of supervison?
learning from demonstrations:copy, infer
learning from observing the world:predict, unsupervised learning
learning from other tasks:transfer learning, meta-learning
learning as the basis of intelligence
single algorithm do?
interpret rich sensory inputs 理解
choose complex actions 选择动作
why deep reinforcement learning?
deep can process complex sensory input
reinforcement learning can choose complex actions.
强化学习在动物大脑中存在
challengings?
humans can incredibly quickly
humans can reuse past knowledge
no clear what the reward function should be
not clear what the role of prediction should be
使用一个通用的算法和环境交互
instead of trying to produce a program to simulate the adult mind, why not rather try to produce one which simulates the child's? If this were then subjected to an appropriate course of education one would obtain the adult brain.-----Alan Turing
介绍了强化学习的背景以及我们如何构建智能设备,后面介绍了课程作业,介绍了架构环境Tensorflow,继续学习!
强化学习提供用来做决策的数学框架。
与深度学习一样 ,deeprl实现端到端的学习。
展望深度强化学习的未来。
深度学习帮助我们处理 unstructured 环境(不能提前预测的,经常变的),例如图像识别、自然语言处理、语音识别等。
是端到端的训练,而不是多步分别优化
强化学习提供了 decision making 的框架。
深度模型 使得 强化学习可以端到端的解决复杂问题。
现在研究DRL的原因:深度学习的进步 + 强化学习的进步 + 计算能力的进步
历史:
reward的设置, 直接reward是非常少的,reward从何而来?除了reward, 还可以有其他的 supervision
猜想:有一个统一的算法处理各种学习
证据:人的不同感觉可以相互转换,例如可以用舌头看,雪貂的听觉皮层可以处理视觉信息(经过足够时间训练)
DRL能做什么,不能做什么?
能做:
挑战(开放问题):
- Deep: can process complex sensory input and can also compute really complex functions
- Reinforcement learning: can choose complex actions
一、介绍了课程内容大纲:
(1)从监督学习到决策问题,模仿学习;
(2)model-free,Q-learning、policy gradients, AC;
(3)model-base 和一些高级问题;
(4)exploration(搜索);
(5)迁移学习、多任务学习、meta-learning(元学习);
(6)开放问题、研究报告、讲座。
二、介绍了什么是强化学习和为什么要用强化学习(有什么优点)。
老师的讲课很细致,首先感谢老师和翻译组的老师们,辛苦了,内容特别棒!
课程主要是针对博士生水平,跟着学习需要一些先决条件,另外使用的是tensorflow实现的,需要python基础。
一共有六次作业,其中最后一次是一个完整的项目,可以组队完成。
可以通过http://www.tensorflow.org/guide/low_level_intro 进行python及tensorflow的入门学习
一、什么是强化学习,为什么研究它
如何构建智能机器,首先智能机器必须具有适应性,是要针对环境的复杂性、多变性、非结构化的问题,深度学习就能够帮助我们解决这类非结构化问题,比如图像识别、自然语言处理等。但是深度学习却没有告诉我们如何决策,强化学习就是这样一种数学框架,能够使得智能体与环境进行交互从而做出反馈,进而形成自己的决策。现在将深度学习与强化学习相结合,就能够具有更加强大的功能,例如可以像一个高级业余选手一样完成backgannom等的游戏。它通过自学习来训练,学习到如何玩游戏,之前的一些方法要达到这个效果是非常困难的。
深度学习方法对于图像或者目标的识别不用像之前的方法一样需要做很多的困难的复杂的特征工程,而只需要进行很多层次的网络的构建,通过自动的特征进行抽取,这两者目的一样但是训练的方法却有不同。所有层都是端到端训练出来的,抽取到的特征并不是有人来进行规定的。这样的方式有两个优点,一个是不需要人工进行特征工程,第二个就是它能够进行最优化的特征选取。
标准的增强学习采用传统的比如线性函数表示的方式,对一个特定问题,首先对其进行特定的编码,之后从中提取特征。但是这些特征很难跟具体的环境的状态或者说状态的转换相关联,就需要找一些相关领域的专家进行咨询,了解其之前的相关关系,这之上又需要很多不同的特征进行线性函数的关联,因此很长一段时间,增强学习的应用受到了很大的限制。
而深度强化学习就兼具两者的优点,能够自动学习初级和高级的特征,并用于增强学习关于环境和状态的转换之间的关系,通过端到端的学习。
二、对于序列决策端到端的学习方法意味着什么
如果一个决策是基于感觉和知觉,在现实中,这一过程会相应的跟上决策和行动。
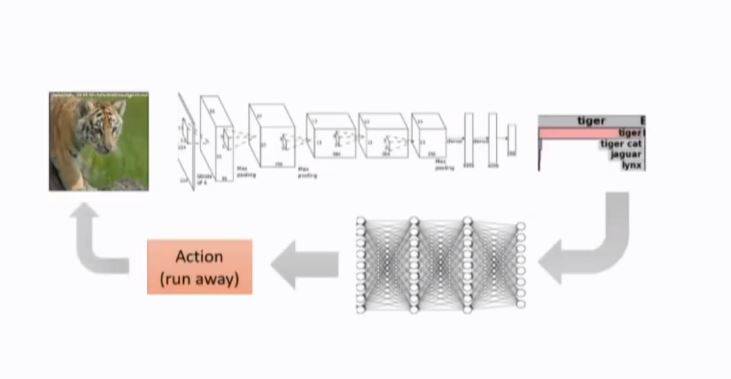
其困难在于需要高级的抽象过程,在一定程度上需要人的指导,感知系统和动作系统在这里需要选择正确的特征抽象,但当你想要联合优化控制系统和感知系统时,就需要知道价值函数。
三、端到端的应用
使用端到端的优化能够克服很多的问题,因为它是根据外界环境来优化得到最终的结果。
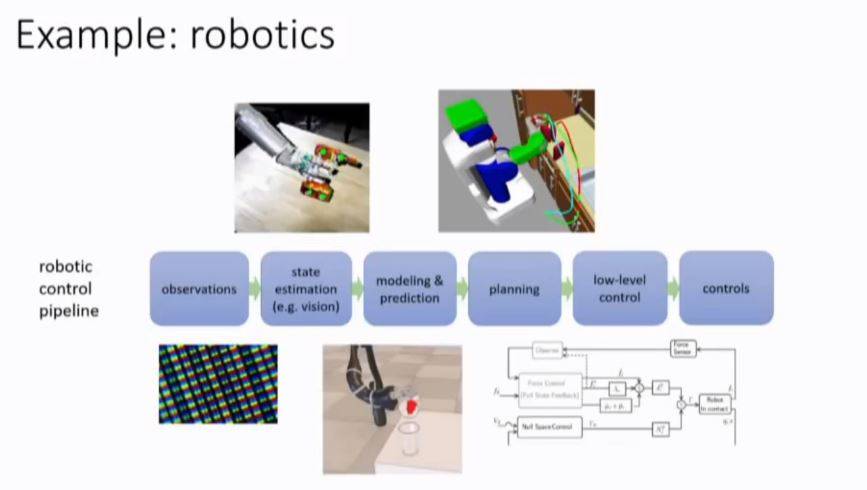
强化学习中我们有个做决策的机构,根据结果进行反馈修正,称之为观测和反馈。虽然在很多领域进行了不同的问题的解决,但是它的公式可以相同。事实上,强化学习是其他机器学习问题的一个泛化。深度学习方法使得强化学习能够使用端到端的方法解决更多复杂的问题。
还有很多的领域能够成功的使用强化学习,比如交通场景管理。
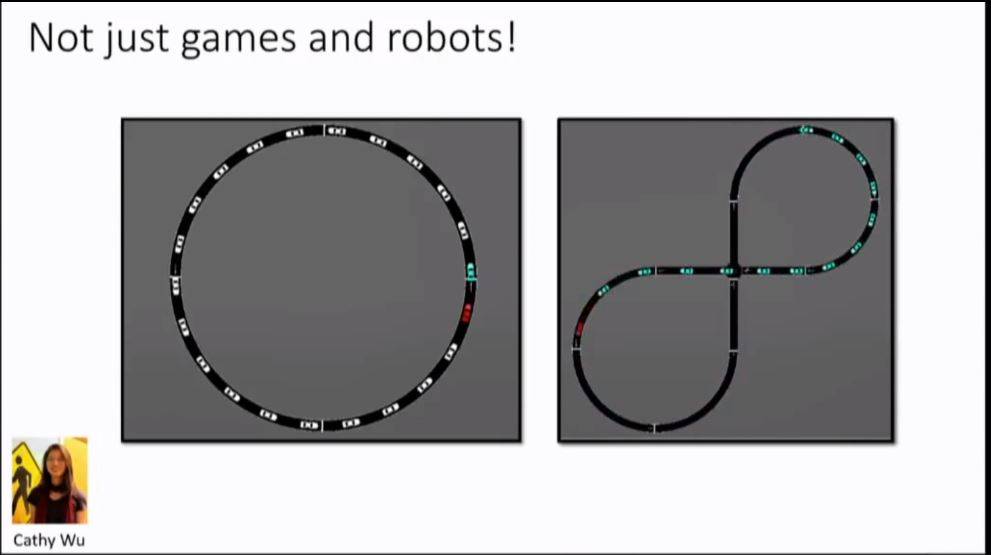
四、现在为何还要学习强化学习
当前很多的技术推进了深度学习的发展,使得之前不能够实现的方法得以实现,加之随着硬件技术的发展和分布式云计算等技术的广泛运用,使得深度学习和强化学习的实现和训练成为可能。

分层学习是现在的前沿研究,之后的课会讲到这个概念,特别是高深主题时。后面还将讲到如何使用循环神经网络提供记忆强化学习智能体。所以概念在很早就出现了,只是缺少一个让其变得有实际意义的应用。
在过去的五年,我们看到了很多领域的惊人成功!

在本课程的作业中这些也将会被使用一半以上,Exciting!!
五、其他能够用以解决的问题
现实世界中的问题还要考虑更多的因素,而不仅仅是将观察转换为行为的一些重点问题。当我们想建立一个模仿于现实世界的环境时,不能够只考虑有一个很完美的完全正确的奖励函数。还有很多高级主题,例如逆强化学习等等。
六、奖励从何而来
奖励是传统强化学习公式中很基本的部分,但是现实问题中,却不是一个简单的问题。在游戏的训练中,奖励函数可以跟得分相挂钩,但是在现实生活中,人们往往不能够简单的知道做一件事是好的还是坏的,即使有明确的定义也不一定能够方便测量,很多时候感知到完成了一件事情可能和完成一件事情一样困难。如果要将一切考虑进去,可能会得到一个极度困难的强化学习的问题。

如果仅仅依靠随机搜索或者人们很擅长推断,可以从其他的地方学习经验,然后模仿下,看看是不是会有好事发生,它可以智慧的判断,然后用不同的方式实现它们的目标 。
预测,人类的很多智能推理是源于预测。预测就可以计划,预知未来的情况。
七、如何构建智能机器
从复杂开始将很难构建,因此要从简单的方面开始,例如首先从一个简单的算法开始,要有各类输入和各种复杂的行为选择。那么为何选择深度强化学习呢?处理复杂的感官输入,例如图像、声音等等,手动设计去理解将会非常复杂,深度能让复杂的函数得以计算,而强化学习则提供了所需的数学体系,为选择行为提供理论支持。
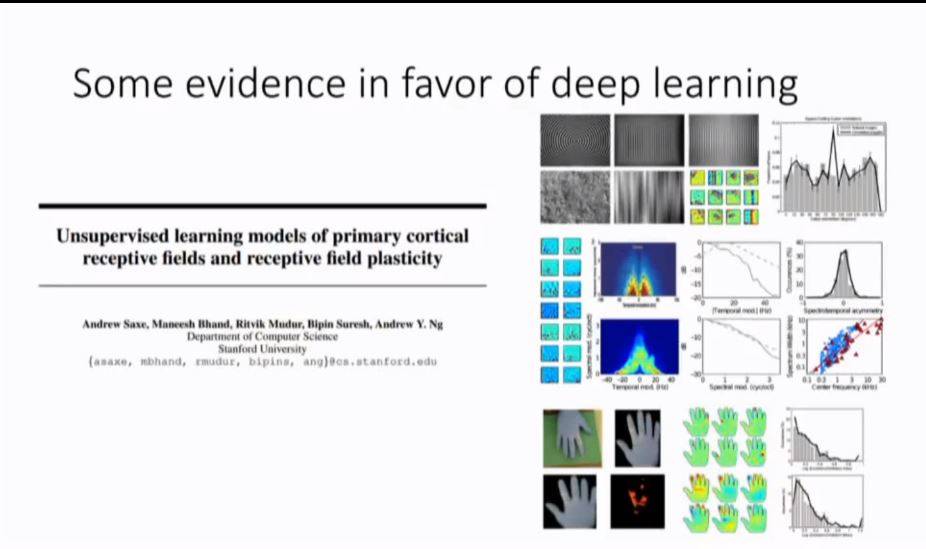
八、适合深度强化学习的领域
很多领域深度强化学习都非常精通,比如棋盘类游戏、视频游戏等,可以通过大量的感官输入学习新的技能。



 客服1
客服1
 官方群
官方群