


与机器学习向深度学习推进一样,强化学习迈向深度强化学习,目标是为了实现端对端决策。
这部分对无人驾驶决策控制块很有启发,值得深入研究
如果两端距离太远,导致太复杂,会失败。因为最开始随机碰到这个奖励的概率太低,狮子猎杀羚羊的例子说明这个问题:如果设置吃到羚羊为最终奖励,那狮子肯定会饿死。
奖励是什么很重要
¥
支付方式
请使用微信扫一扫 扫描二维码支付
请使用支付宝扫一扫 扫描二维码支付
与机器学习向深度学习推进一样,强化学习迈向深度强化学习,目标是为了实现端对端决策。
这部分对无人驾驶决策控制块很有启发,值得深入研究
如果两端距离太远,导致太复杂,会失败。因为最开始随机碰到这个奖励的概率太低,狮子猎杀羚羊的例子说明这个问题:如果设置吃到羚羊为最终奖励,那狮子肯定会饿死。
奖励是什么很重要
supervised learning and imitation learning
P(a|o)
P(a|s)
状态s1,s2,s3...之间独立
或依赖于前一状态(马尔可夫链)
imitation learning
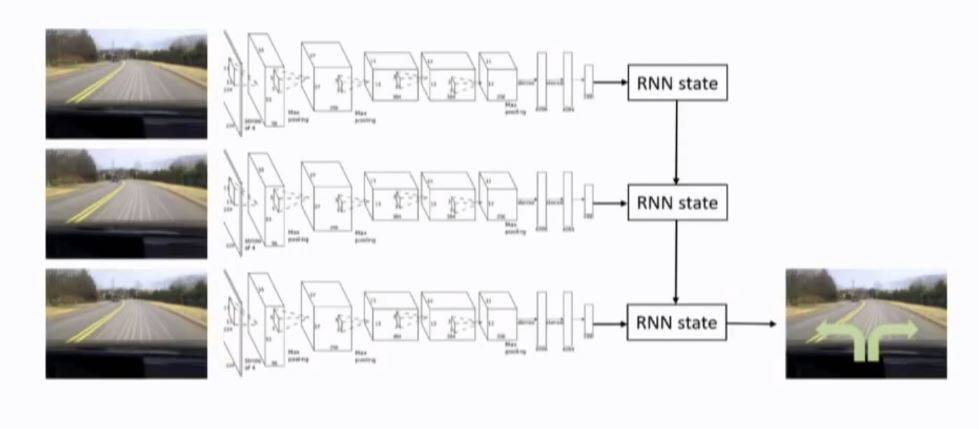
behavior cloning: 自动驾驶领域,学习人类的观察o和驾驶方式a
这个方法不好:误差积累
NVIDIA用三个摄像头互相调整转向角度
解决分布不匹配问题?
人工引入噪音,让算法去纠正它
DAgger:Dataset Aggregation
goal:collect training data from P(pi) instead of P(data)
1、train P(pi) from human data D
2、run P(pi) to get dataset D(pi)
3、label D(pi) with actions a(t)
4、aggregate D=D+D(pi)
无法拟合专家行为的情况
1、非马尔可夫行为(不管现在的状态,有自己的计划)
2、多模型行为(output mixture of Gaussians, latent variable models, Autoregressive discretization)
output mixture of Gaussians
模型输出多个均值和方差
latent variable models
加入额外的输入(随机数)
autoregressive discretization
总结:
一些技巧(左右摄像头)
稳定的趋势分布
一些策略(DAgger)
更好的模型
other topics in imitation learning :
structured prediction
inverse reinforcement learning
imitation learning's problem:
humans' data finite(数据有限)
human are not good at providing some kinds of actions(一些数据不好得到)
能自主学习吗?
c(s(t), a(t)) cost function
r(s(t), a(t)) reward function
数值上互为相反数
总损失的期望值
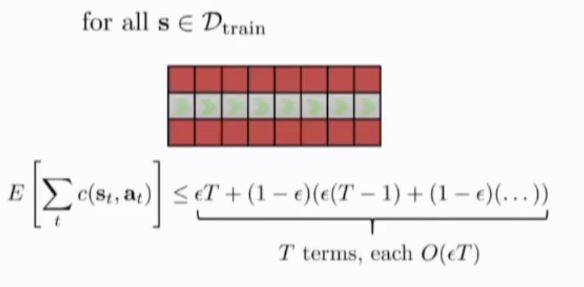
就算概率足够小,但路径足够长,损失也会很大
改变假设,使得同分布,收敛于episio*T
本节课内容:
一些标记:输入信息observation
输出信息action
参数化的模型即策略
状态
s与o的区别在于,o为观察得到的信息,如一副图片等;s为环境的物理信息表示,如位置等。
状态转移方程
马尔可夫性质:如果当前状态精确可知,则未来的状态相对过去的状态独立。
行为克隆behavior cloning:将人类数据作为训练数据进行监督学习
缺陷:微小误差会演变为巨大误差
Nvidia方法:增加左右两个摄像机学习调整纠偏
一种方法:从一个稳定的控制器stabilizing controller中进行监督学习
DAgger算法:使人类数据p data等于策略行为数据,运行pi theta 然后人类为其加入标签
缺陷:很多任务让人来打标签并不自然,也需要很多资源
对于非马尔科夫决策:利用之前的所有观察信息
使用如RNN的算法
对于多模型行为:
混合高斯分布:输出N个均值N个方程,也叫混合密度网络
隐变量模型:在末端加入一个随机的噪声,利用噪声来选择输出
自动回归离散化:对于高维连续的行为空间,分步进行抽样,每步离散一个维度的分布,并将抽样的结果作为下一个维度的输入。
这样网络只是线性的增长而不是指数的增长
例子1:无人机穿越森林
例子2:利用LSTM和混合高斯分布控制机器人
模仿学习的问题:
成本函数
奖励函数
关于成本函数的分析:
假设策略pi发生错误的概率小于等于epsilon
即
都取最大值epsilon
则T个时步的损失为:
数量级为
更强的假设:对于与训练数据同分布的数据,错误上限说epsilon。意为即使数据不严格与训练数据一样,也认为其上限为epsilon。
对于DAgger算法,则p train看作和p theta相同
则损失的期望为
1.深度强化学习,是引入深度学习技术的强化学习技术
2.深度强化学习,注重与环境交互,在和环境交互中持续获得智能
3.深度强化学习,不必从模拟高级成人智能开始,可以先模拟低级儿童智能
需要机器学习基础和强化学习相关基础,因为主要是面向博士生的课程。课程默认Tensorflow作为编程框架,自动微分课程
这里讲到RL是提供决策的。后面说道生理上的奖励来源于bg,不过最初真实的是来源于食物奖励,信号并不仅仅给bg,还对amyg有作用,行为的直接控制是bg,类似rl中的pg,而q-learning中的value则类似amyg,真实的控制是两个一起的,里面情况极端复杂,详细可参考sg的motivation model与telos model。
本节主要对Deep RL进行了简介, 没有涉及具体的算法。
相对于传统的机器人控制,深度强化学习提供了一种端对端(end to end)解决复杂连续控制问题的方法。
随着近年深度学习的发展、强化学习的发展以及计算能力的发展,现在正是学习深度强化学习的好时机。
不同于电脑游戏,现实世界中的Reward十分难以定义,也不易进行量化。
几种思路:
1.从模仿中学习:直接重复观察到的动作;从观察到的动作中得到reward(逆强化学习)
2.从观察世界中学习:学习预测
3.从其他任务中学习:迁移学习;元学习
人类初始拥有一些技能如走路,但人类更多的技能由学习得来,如开车。
构建一种“简单的算法”拥有学习能力可能是问题的关键。
这种算法需要1.接受大量不同的输入
2.选择复杂的输出
深度强化学习正好可以做到这两点。
当然现阶段的DRL有着学习速度慢,不能重复利用现有经验,奖励函数定义困难等缺点,距离人类智慧还有一大段距离。
强化学习三个要素:状态、动作、回报。智能体通过智能决策系统,做一个动作,之后观察环境,得到下一个状态和回报,然后将(si,ai,ri,s(i+1))用于更新该策略网络/值网络,以便下次作出让回报更大的动作。
强化学习的意义:free of model,我们无需手动设计出复杂的特征算子,只需要输入一张图片,强化学习算法就可以端对端的输出需要的结果(动作/标签等)。
个人感觉监督学习任务是给定输入我们预测一个输出,连续或者离散的,是从输入到输出的映射;而强化学习则更高一层,是主体和环境之间的交互,是一个连续的决策过程:主体对当前环境做出最佳决策,这个决策的过程也可以视为预测任务,去预测一个最佳输出,不断重复这个过程。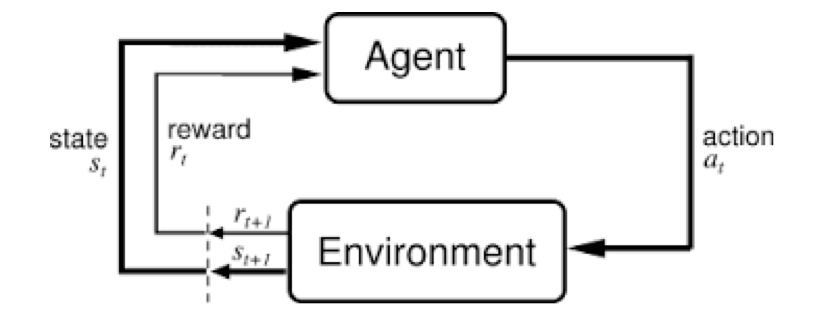
如视频中所言,本质上强化学习这个任务可以包含监督学习。


 客服1
客服1
 官方群
官方群