

¥
支付方式
请使用微信扫一扫 扫描二维码支付
请使用支付宝扫一扫 扫描二维码支付

第一课:
1、从计算机视觉上的发展来看,standard的方法是手动标注特征,但是通过深度学习,端到端的方式使得特征自动提取,看起来更加智能,人的参与干涉更少
2、从强化学习来看,standard的是需要找到正确的特征使得增强学习算法表现优异,但这通常是很困难的,但是通过深度强化学习,通过很多特征表示层,这样端到端的学习,可以不必依赖于人工指导,可以自动正确地得到底层特征抽象来帮助我们做出高层的决策
3、而事实上我们对于奖赏机制的定义于现实生活中通常是很困难的,而这里则又衍生出了模仿学习,通过模仿,我们不必自己需要获得奖赏后才能学习到某个行为对于我们的重要性,但是通过模仿学习,我们可以ignore这个就我们人类而言的某些在基底神经节的一些更复杂的机制
4、而通过观察这个世界,我们可以学习来做出一些预测,而通过这些预测,我们就能够基于未来的预测而做出我们现在所想要达到那个预测的行为。
介绍一个blog,https://zhuanlan.zhihu.com/p/32652178,看完视频课程在看这个专栏其实收获还是很大的。友情推广。
介绍一个blog,https://zhuanlan.zhihu.com/p/32598322,看完视频课程在看这个专栏其实收获还是很大的。
本课从简单的任务说起, 针对一个自动驾驶的问题,分析了可行的策略.
最简单的,模仿学习. 分析了模仿学习理论上的问题和现实中是如何解决这些问题以便让模仿学习可行的.
更为复杂的, 有些问题不能简单的用模仿学习进行训练, 有些问题受困于数据量, 这就引出了本课程的核心, 强化学习.
本课中还给出了强化学习的几个常用记号:
Agent - 本体。学习者、决策者。
Environment - 环境。本体外部的一切。
s - 状态(state)。一个表示环境的数据。
S,S - 所有状态集合。环境中所有的可能状态。
a - 行动(action)。本体可以做的动作。
A,A - 所有行动集合。本体可以做的所有动作。
A(s),A(s) - 状态s的行动集合。本体在状态s下,可以做的所有动作。
r - 奖赏(reward)。本体在一个行动后,获得的奖赏。
R - 所有奖赏集合。本体可以获得的所有奖赏。
St - 第t步的状态(state)。t from 0
At - 第t步的行动(select action)。t from 0
Rt - 第t步的奖赏(reward)。t from 1
Gt - 第t步的长期回报(return)。t from 0。
1. It is interesting to see that under the umberella of policy grident , REINFROCE method , as one MC approach, comes first and after that value function fitting approach comes later. It is very easy for us to have a confusion on understanding PG. IMHO, the key points here are like this:
1.1. G(s,a) unbiased and biased estimation
1.2 Variance reduction idea
2. Under some policy, the accurate Q(st,at) is the reward plus the expectation on Value funciton of the next state. As unbiased estimation, one sample V for the next state is used to combine with the reward.
3. The tradeoff between the AC based and the MC based lies in the bias and variance.
For AC: Lower Variance but higher bias if value is wrong(it always is)
For A-MC: no bias, higher variance
4. Generalized advantage estimation (GAE) is good framework to give a consist way to consider the tradeoff
Polilcy Grident method:
1. All the stories about PG come from the definition on the expection of total rewards.
That is, suppose you get a distribution on the generated trajectory and each trajectory will return a total reward , the unbaised estimation about the expection is the average sampled total reward.
2. The goal of the RL is to change the trajectory distribution by reinforcing those good ones and lower the bad ones so that the total rewords will increase.
3 Now the task has been transferred to a optimization problem. A gradient ascent method is then the first choice. The key point is how to calculate the grident to the parameter that controls the trajectory's distribtion
4. A trick on policy grident calculation is to work on the log policy rather than directly on the policy. With a series of transformation, the core problem in PG is how to reduce the varation, which may affect the policy reinforcment badly.
5. The simplest variance reduction method is substract a baseline named causality or something like that. It works in that it really lowers the returns mathmatically
6. To improve PG , two places are worth to consider : the return and the baseline.
1. Since a monte carlo process is taken, the return can be accumulated for single trajectories and sample again and again.
2 . Or the return could be fit by a non-linear function.
3. The baseline can be fit with another nonlinar function. it is actor-critic method.
Summary:
Policy grident is a straitfoward algorithm that can be easily understood and well used in many circumstances such as alphago. It combines the exploration and exploitation smoothly. but as one online policy algorithm, its downside lies in the sample effciency. Though importance sampling could come as one remedy, it seems not wildly used so far.
第五讲 part(一)
强化学习优化目标:最大化total reward function
policy: state(观测)条件下a(action)的概率分布
在DRL中,用DNN来表示policy ,用某种参数theta的函数来近似拟合 (在神经网络中,theta即代表网络的weights)
policy pi 基于状态s给出action a的概率分布:如果动作a为离散变量,在网络最后加一层sofrmax层得到action的categorical distribution;如果a连续,可能是网络输出某种连续分布的参数比如高斯分布的均值,方差
在强化学习中,学习过程是顺序的:在决策过程中,运行中的状态本质上是由环境控制来生成下一个状态的,所以环境是某种未知的概率分布p ,给定状态s和行动a,来产生下一个state s', 因此可以将环境看做trasition dynamics(和policy共同决定下一个状态)。因此有了policy就可以通过和环境交互来optimize 整个决策过程(目标是最大化 value function)
把一个episode中的(state,action)序列叫做 trajectories,对轨迹分布建模
![]()
简写为p_{\theta} (\tao)
目标是求对所有trajectories对应的每一个state-action pair 的 return reward function 做概率加权求和(总奖励的期望值)的最大值对应的\theta(也即是我们的policy)
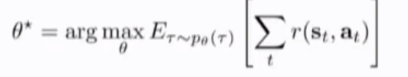
finite horizon case(把求和放在期望外面,是对每个timestep的state-action pair 求 期望,对应的概率分布不再是p_{\theta} \tao, 而是timestep t时刻每个state-action pair 出现的概率,最后对于不同时刻t的期望求和)
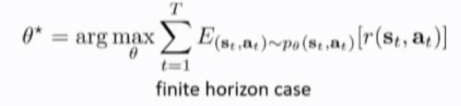
infinite horizon case(马尔科夫链的静态分布(由环境的dynamics和policy pi_{\theta}共同影响))
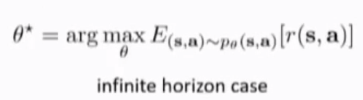
这次课程主要介绍finite horizon case
分两步走:evaluation the value function and improve policy
评估目标函数
由于特征空间维度为 (n+m)* T 相当高维的向量,直接求解不太可能,因此选择近似解,将优化目标记为j(\theta):
求解近似方法:采样:roll out your policy,得到执行policy过程中的每个时间戳t的state-action pair(叫做一个episode),演绎多次获取多个episode,因此可以简单地求均值得到estimate的无偏估计(Monte-Carlo),无bias 但是high-variance
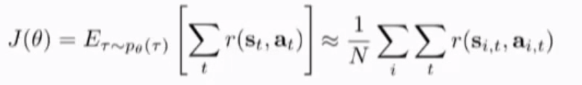
优化policy参数
直接的方法,计算这个表达式对变量的梯度,朝梯度方向更新网络参数(更新policy)
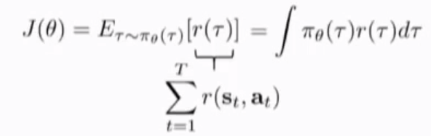
对 theta 求梯度,由于积分是线性运算,可以将积分与梯度号交换位置
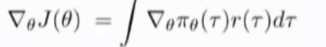
由于\pi_{\theta}(\tau)的梯度很难计算,因为其中包括未知量:transition propobilities.
trick:
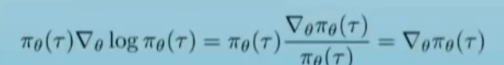
可以逆向运用上面公式,可以发现让然对pi(\tau)求期望,写成期望形式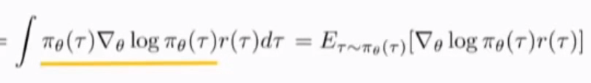
因此对上述期望求梯度仍然是个期望,把pi_{theta}(\tau)写成完整形式(就是上面的p_[\theta](\tau))就是policy \theta 下的trajectories的联合概率分布,写出log pi的具体形式为(log初始状态概率 +t求和( log t状态下的action分布 + log t+1 的转移状态概率)),直接替换上式中的log \pi_{\theta}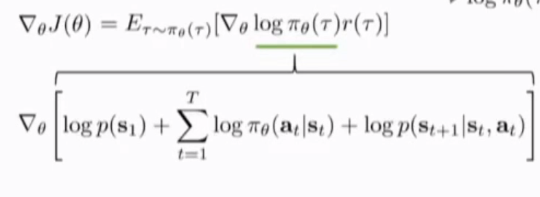
注意到,只有第二项是与theta有关,替换原式得到policy gradient 的表达式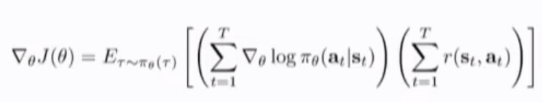
由于策略pi梯度已知(neural network),一次上式子的所有量都已知,但是随机变量仍然为高维向量,仍然无法求得解析解,采用采样值的方法可以估计
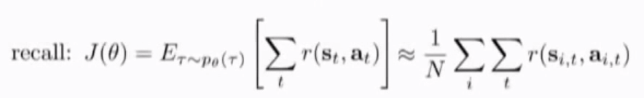
因此我们得到表达式
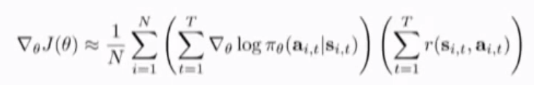
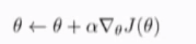
上式为迭代表达式,可以选择其他优化算法,必须加上momentum项或adam算法
问题:使用deterministic policy 时,梯度为0:后续讲到q-learning 以及 value-based methods的时候又会谈到
强化学习算法框架
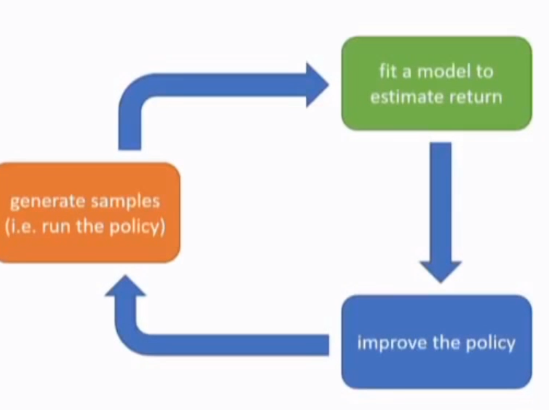
生成样本数据(roll up the policy),使用sample estimating return (evaluate), 更新改进策略(improve)
这个和david silver 的rl课程中讲述的 GPI(Generalised Policy Iteration) 框架大体相同
likely ratio policy gradient algorithm: pseudo-code:
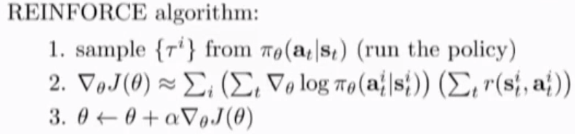
效果 extremely poorly,提升方法:variance reduction
公式的直观含义
pi----policy 给定state条件下action的概率分布:就像在监督学习中训练分类器:得到给定images条件下label的分布(解决极大似然问题---试图调整参数使得最大化给定input的output的log似然函数)
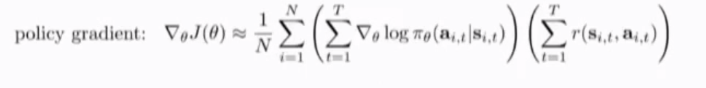
上式第一项直观化为给定st对于at的关于参数\theta对数似然函数
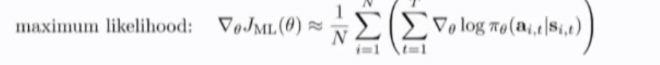
因此形象化理解就是,在nueral-network中输入training data(st为input,at为label),训练得到策略分布---给定st下at的似然分布

并不是巧合,这相当于对所有的采样值被评估函数加权(评估函数意思是似然函数)
并不是对所有样本都输出更大的概率,而是对于good sample ,增加他们的概率,而对于bad samples,降低他们的概率(通过似然函数的加权提现----越接近策略分布的采样会分到较大的权重,反之)
Example:Gaussion policies
在视频里展示的训练小人跑步的例子中,policy是连续值,假设用高斯分布来表现这个策略。均值和方差(先不考虑,设为常数)由neural network 给出,先写出策略的log分布:f(st)为nn估计的action分布对应的label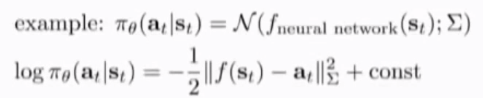
得到对应的梯度表达式
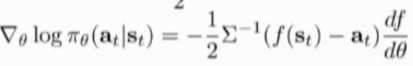
f是neural network,计算网络的输出f(st),计算与at的残差,通过反向传播得到df/d\theta的值
What did we just do?
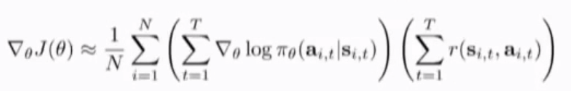
在最大似然估计项中,用奖励函数项对其加权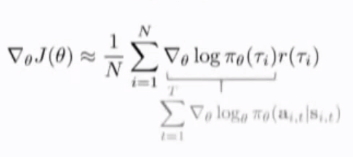
简写,去掉求和符号,用\tau代替整个episode的state-action pair,与最大对数似然函数的区别就是多乘一项r,直观来看就是生成几组样本,一部分好,一部分差;当你应用policy gradient时,希望算法提升好的样本的对应的概率,最终使得奖励函数的期望更高,同时通过不断地梯度更新使得正确的action更多,所以算法最终迭代到最优的policy(formalize a notion of trial and error learning)
Partial observability
在推导策略梯度时没有使用任何Markov 性质(当前已知时,未来与过去无关),因此常规的策略梯度可以被用于局部观测(将s替换为o),不需要任何修改。
在后面介绍的actor-critic算法和value function 时,这一性质不一定成立
What is wrong with policy gradient?
过大的方差:对于有限的采样来说,estimate虽然是无偏的,但是会产生很大的方差。因为只是沿着梯度优化(梯度依赖于你的采样,而采样是任意的非稳定的)而不是沿着一条直线轨迹优化,会造成估计值的变化幅度过大,如果大于你朝着目标点所做的优化(解释非常清楚),会使得算法最终收敛在一些较差的位置或相当长的时间才能收敛(需要很小的step-size)
直观的解释:
下面的例子中,将trajectories利用PCA投射到一维(x轴),y轴为沿着trajectories的reward,服从高斯分布。我们产生三个随机值,
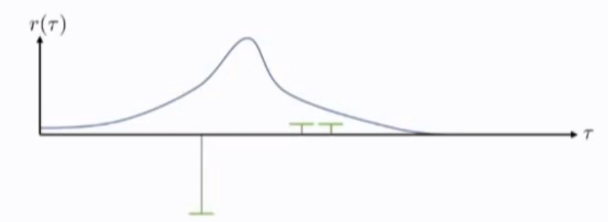
右面两个较低但是有着正的reward,左边是很大的负奖励,从图中可看出他们是来自这个分布的采样值,我们期望使用策略梯度来调整策略,分布应该向正奖励的采样值移动(右),得到新的策略(虚线表示)
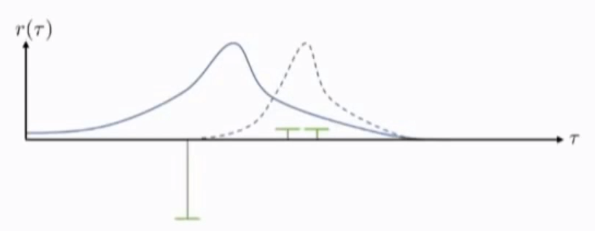
新的policy使得产生负奖励的样本的概率降到最低。
之后我们对reward function加上一个大的常数(整体趋势应该不变),所以最终的结果不会有很大的改变(微小的右移)
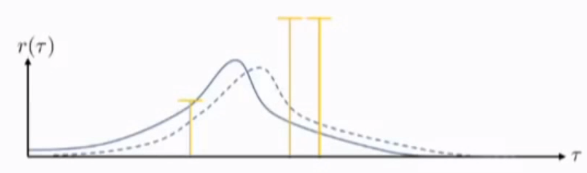
更坏的情况:对于上述两个good sample ,他们的reward function r(\tau)都是0
策略移动向右还是向左取决于从哪边开始:先采样到good sample 还是 bad sample
如果从bad sample右边开始,策略分布会向右边移动更长;如果从bad sample 左边开始,策略分布会向左移动,从而完全的忽略掉good sample(因为他们的reward是0)
这种看起来不重要的转换实际上影响了梯度
Part(二)Variance Reduction
Two Tricks that helpful
FirstTrick
assumption: future doesn't affect the past
Causality: policy at time t' cannot affect reward at time t when t < t'(未来的policy 不会影响之前的reward)
对两个求和的乘积的公式做变形,使得整个trajectories的总回报放入到policy的求和公式中,变为
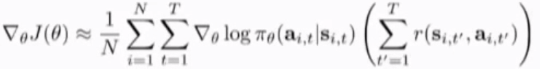
可以将t之前的所有t'的reward去掉(当前的policy 不会影响之前的reward),改变后面的求和下限t'=t而不是t'=1
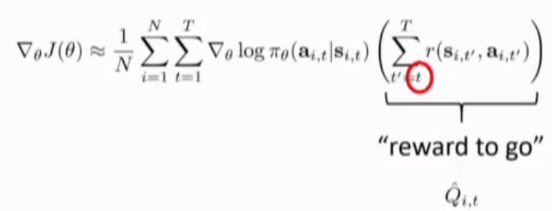
实际上与Q value function 有着密切的关系(在david silver的课程中,q value function 实际上还要加一个discount factor \gamma)
值的注意的是在每个timestep t,policy是相同的(shared across all time steps)
在finite horizon problem中, optimal policy is a time varying policy,在不同的timestep可能有不同的action
在上述的方法中,是直接暴力的从策略类里找到最佳策略 :限制policy class 成为一组time invariant policies
为什么这种方法能够削减方差?
删掉了t之前的reward ,求和变小,方差变小
Second Trick
如果reward都是正的,那么所有的概率都将试图提高
改进:将原本的奖励与logpi的梯度相乘变为logpi的梯度与奖励减去平均奖励的值相乘,即
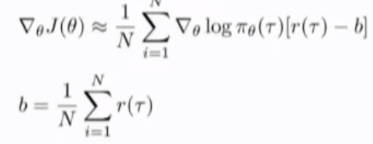
从而让获得比期望更高奖励的action的概率增加,获得比期望更少奖励的action的概率减少
substract a baseline is unbiased an expectation
prove:
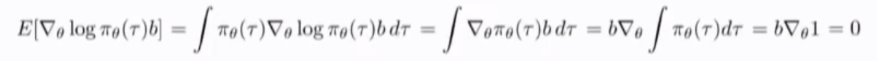
意味着从reward中减去一项或者加上一项常数,将会得到和期望一样的结果
但是对于有限数量的样本,不会得到相同的方差,方差会改变,但是期望不会变化,因此可以选择b来最小化方差
事实上,平均baseline并不是最好的baseline
Best Baseline
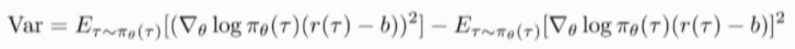
第二项中,减去b并不会改变原来的期望值,因为上一步中我们证明grad of logpi * b的期望值为0,所以第二项对b没有影响,只考虑第一项
使用g(\tau)代表grad of log pi (\tau)
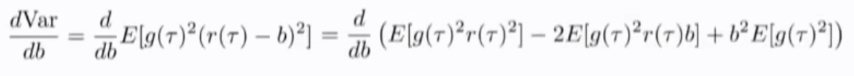
去掉与b无关的第一项,把导数为0,得到b
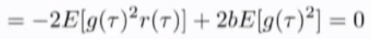
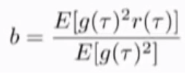
所以使得方差最小的b的值对应上式
This is just expected reward, but weighted by gradient magnitudes
不是所有的reward都是同等加权,而是取决于他们对于梯度的贡献度
在每一个参数向量元素都有个独立的baseline b, b的获得是该梯度的大小加权的预期的奖励
通常只是使用expected reward baseline
第五讲 part(三) On policy and Off policy
policy gradient 是 on policy 算法
on policy :每次改进你的策略,生成新的样本
在policy gradient中,我们估计梯度是通过建立期望的无偏估计,而这种估计要求样本从当前策略(想要更新的)来产生。
当你更新policy时,之前生成的样本将不再有效估计策略梯度,而是需要根据新policy生成新样本,这就是为什么RL算法通常要重复这个序列过程
Trouble:当处理复杂的policy classes 像神经网络(复杂的非线性方程),因此step-size应该相当小,因此这种on policy 学习实际上非常低效
Off-policy learning & importance sampling
What if we don't have samples from pi_{\theta}(\tau) or samples from other policy pi^{bar}(\tau) instead to estimate out policy gradient
Importance sampling
一种基于计算在某个概率分布下的函数的期望的方法,当你没有从概率分布p(x)中获得样本,但是从其他分布q(x)中获得样本
通过上式变换,我们可以看到从原先的对p(x)求期望变成对q(x)求期望,括号里的f(x)前的比例p(x)/q(x)为importance sampling
估计已知的分布importance期望来代替计算某些未知分布的期望 ,对应于我们的估计策略梯度问题,p代表pi_{\theta},q代表pi^{bar}.
target:从pi^{bar}中采样来估计p_{\theta}的梯度(注意是对pi^{bar}求期望)
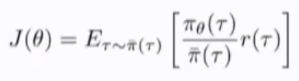
由于pi_{\theta}(\tau)依赖于初始状态概率,action概率以及状态转移概率(未知量),实际上无法直接计算pi_{\theta}.也无法直接计算pi^{\tau},可以展开着两个式子,消去共同的项,得到简化的比率。因为这两种policy分布是在同样的环境中进行的,大多数是可以抵消的
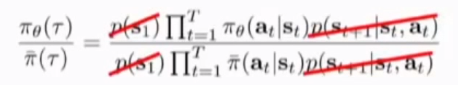
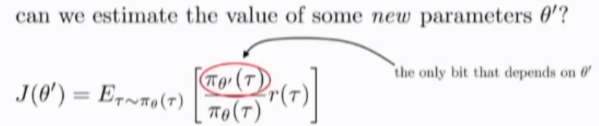
所以关于j(\theta') 的梯度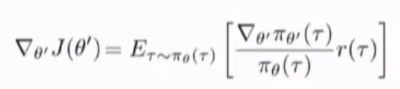
利用convenient identity
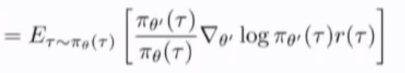
上式中之前的policy(\theta),现在被importance weights所加权,以及在旧参数下的期望,开始使用相同的参数向量,从过去使用计算梯度过得policy中采样,两项消掉
使用improtance sampling 来对聪theta采样的policy gradient 求导
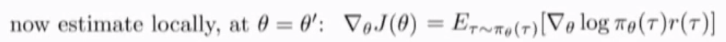
而当theta != theta' 时,记得policy的比率只通过action概率的比例获得的,为了避免过大过小的连乘结果,进行归一化,还可以做得优化是,记录前后的causality,也会影响importance weights。
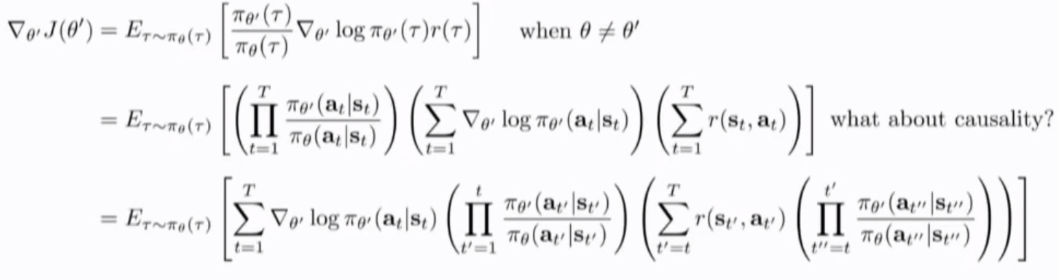
将左右两项都分配到log pi的大的和项中,并再次把连乘项分配到r中,注意求和下限的变化,importance ratio 分为两部分,一部分为t’从1到t, 另一部分从t到T,从t到T的部分分配到r中,r的求和下限根据policy只影响未来的reward,改写为t到T,因此剩下一部分的importance ratio分配到r中t'' 从t 到t'(未来的action不影响 现在的 importance sampling)
不会随着时间指数变化的policy gradient estimator:first-order approximation for IS
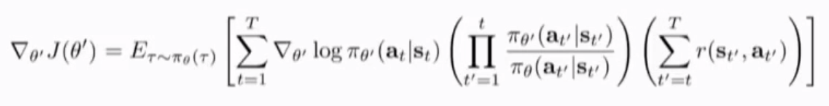
但仍然是T的指数函数,将分别在at ,st的概率下求期望
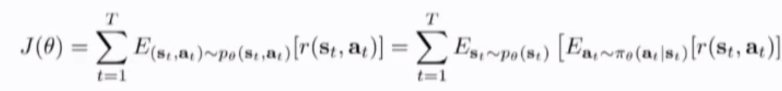
分别对state 和actions 做importance sampling
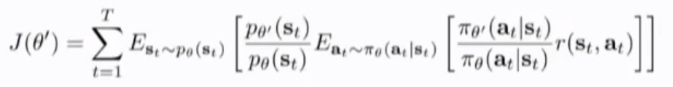
因此action的importance sampling ratio 不再随时间呈现指数级变化,但是我们不知道state 分布,简单的忽略state的importance ratio不正确,当theta和theta' 完全不同时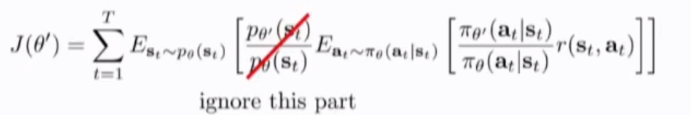
类似于在imitation learning 中将distribution 分成产生error的部分和不产生error的部分,因此对于error有一个bound
因此当theta 和 theta' 非常接近的时候,误差是有界的
上式子的importance sampling 不是t的指数函数,因此非常有实用性
Policy gradient with automatic differentiation
PRactice in policy gradients
gradient has high variance
- consider using much larger batch
- tweaking learning rates is very hard
- Adaptive step size rules like ADAM
- policy gradient-specific learning rate adjustment methods
解锁太慢,直接在youtube上看了第二课。
第二课主要讲了:
1.
原理很容易理解,就是人生成了操作序列,然后我们认为人的决策都是对的,所以将该序列的状态作为输入,决策行为作为输出(即每个动作是一个分类,人选择的这个分类概率为1,没有选择的概率为0).然后监督学习就可以了。然而可惜的是没有足够多的负样本。所以当机器学习完毕后肯定有误差,所谓差之毫厘,谬之千里,机器就跑偏了,然而没有跑偏了的样本,导致机器不知道该如何回归正确的路径。所以这里说了三个方法:1.采样三个摄像头,左中右各一个,左右2个就是用来纠偏的,其图像对应的动作分别是向右和向左,经过训练机器就知道如果跑到左边了需要向右。这样我们就有负样本了;2.人工纠偏,就是机器决策并跑了一段距离,获取了一个序列s1,a1,s2,a2...然后人再根据这个状态序列也操作一遍从而获取了纠偏行为样本,机器再学习如何纠偏;3.加噪音,依然是构造纠偏数据,但是是在已有的正确路径上增加噪音来自动构造纠偏样本,但是增加噪音后需要expert,例如人,提供正确的纠偏动作,但是无论是人还是具有expert能力的模拟器都是困难的。
2.非马尔科夫和多模型
非马尔科夫就是要增加时序,所以可以考虑RNN,但是CNN或者self-attention也应该是可以的吧。alphago就是将历史的8步棋都作为输入。
多模型关键是对动作的分类,如果是softmax输出,输出的总是离散动作的选择概率,就是一个多分类问题,所以如果是连续动作必须要离散。离散成功后多模型就自然解决了,因为选择的是具体的动作,这就是第一个多高斯分布的方法。但是如果是回归模型,输出的是动作的各个维度的值,例如方向,速度等等,就可能会被平均了,这就需要增加隐变量,实际上就是把动作的维度映射到另外一个空间中。例如绕过障碍向左和向右都可以,我们不能把这个给平均到中间方向,所以如果映射到高维,就避免了平均问题,因为不同的维度是不能平均的,形象一点理解就是我们把方向分成左路//中路/右路三个中间维度(但是实际上神经网络学习出的隐状态是无法直观理解的),最后在加权合并为最终输出的方向,最终输出方向很可能概率向左或者向右,而不会出现在中间,因为中间隐变量几乎没有输出。这就是第二种方法,第三种是如何对高维度连续动作进行离散,课程中说一个个维度分别离散,而不是组合起来,这就又有点像是RNN了,将多个卷积串连起来,每次只输出一个维度。
1.首先这门课程需要的铺垫性课程:CS189,CS289,CS281A
2.介绍Computer Vision、Deep Learning和Reinforcement Learning概念。
3.介绍Reinforcement Learning的应用与当前研究进展。


 客服1
客服1
 官方群
官方群