


学习这门课程的先验知识:
- ML(可以上CS189,CS289,cs284A)
- Tensorflow基础(作业提供的代码是tensorflow的)
- python基础
这门课会包含的内容
- 从监督学习到决策问题
- model-free的算法:Q-learning,policy gradients,actor-critic
- 先进的基于模型的学习和预测
- Exploration(RL中的一个概念)
- 迁移学习,多任务学习,元学习
- 更多高级话题
五个作业,一个项目
- homework1:模仿学习(如果期间tensorflow不清楚或者pytorch不是很清楚可以去补习一下)
- homework2:实现policy gradients
- homework3:Q-learning and actor-critic algorithms
- hoemwork4:Model-based reinforcement learning
- homework5:Advanced model-free RL algorithms
- Final Project:ICML或者NIPS级别的workshop papaer(顶会论文)的同学可以考虑
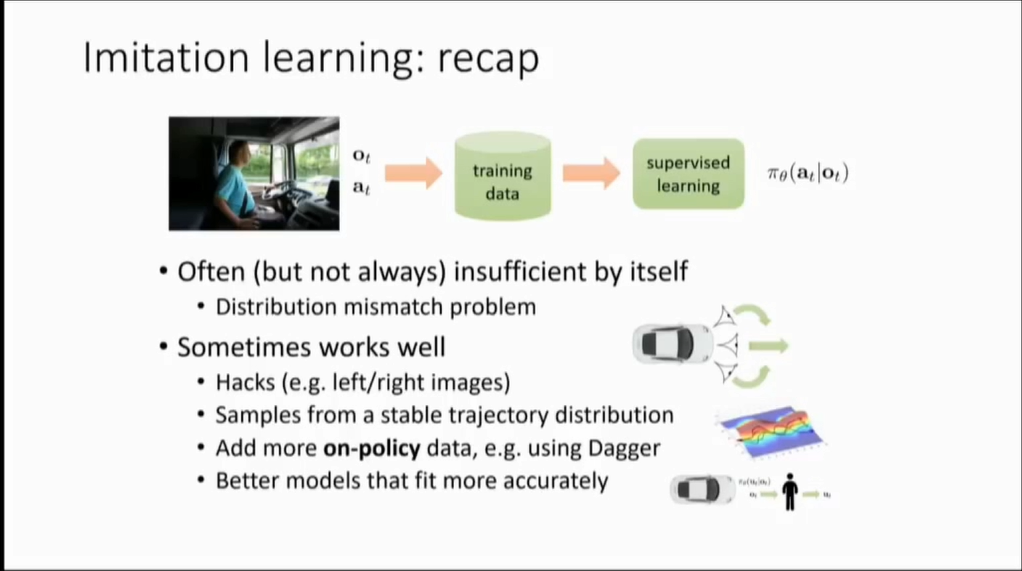
DL在很多非结构化任务上有着良好的性能,比如图像识别、语音识别等,但是DL尚未解决如何去智能决策的问题,RL尝试去功课这一难关。RL通常由很简单的数学模型描述:agent <-> environments,agent做出决策,而environments给出consequeces,也就是我们观测的奖励。
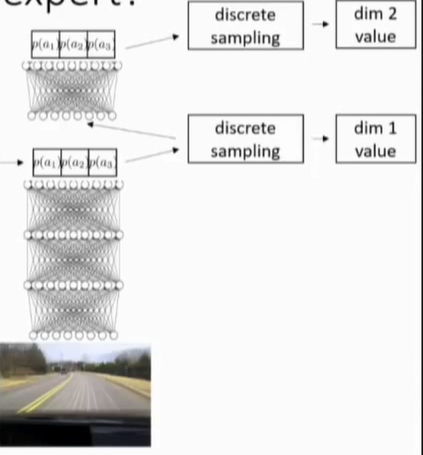
而现在DL和RL的联系越来越紧密,传统的CV需要提取特征,如何再讲小的特征变成大的特征,然后经过分类器最后得到结果,现在DL的出现使得中间的过程只需要使用端到端的网络,并且不需要人工设计特征算子。RL的传统方式,首先要对游戏进行编码,然后从这些编码中得到可以用于决策的特征(难,可能需要问专家)然后同样的提出更高级的特征,最后你会使用liner policy or value fuc 去学习。DL和RL的结合,使得上述features的寻找更方便,并且不经限于此。
强化学习的框架可以用于以另一种复杂的表达形式表示现在许多DL问题,比如CV,NLP,而其中的深层网络可以使得RL有更高维的state以及action spaces。
可想而知,假设RL中有一种算法可以使得所有的任务都可以进行学习,那么它将具有以下的特性。
- 能够接受各种各样高纬度的输入
- 能够从无穷多的动作空间中选择决策。



 客服1
客服1
 官方群
官方群